I’ve just come back from HPC Special Interest Group (HPC-SIG) and HPC Champions (formerly ARCHER Champions) events on the 25th and 26th of Feb in Bath, so thought I’d do a write-up. There’s updates on Liverpool and Bath’s cloud HPC, ARCHER 2, Tier-2 HPC refresh and how you can get extra GPU compute for your research!
Cliff Addison (Liverpool) and Steven Chapman (Bath) gave talks on their respective university’s integration of cloud infrastructure into their HPC offering.
There are many things that can cause a HPC system to go down including power cuts, cooling infrastructure failure, planned and prolonged system maintenance, relocations, etc. The cloud can provide an extra resiliency by allowing on-demand clones of nodes to be brought on-line relatively quickly in times of failure or to provide extra compute capacity.
Liverpool has been trialing cloud bursting on Amazon’s AWS through Alces Flight. Their setup uses local gateway/appliance nodes to provide authentication and supply node images. Additionally, front-end login nodes and storage are hosted locally and user’s data are pushed to the cloud on-demand. Cloud storage was still found to be relatively expensive and cheaper archival storage (e.g. glacier) took too long to retrieve data when needed. Cliff also mentioned that the cheapest nodes may not be the best e.g. for AWS while t2.medium is cheapest, c4.large and c5.large allows work to finish faster.
Bath is still running a pilot project with Red Oak Consulting on Microsoft’s Azure platform. Early issues encountered are unexpected clauses in software agreements and delays in cost reporting and ability to map true cost to workloads. They expect the trial to be completed by summer.
ARCHER, the UK’s national supercomputing service for problems with very large compute requirements (e.g. climate modelling), is due to shut down this year and will be replaced with the ARCHER 2 system.
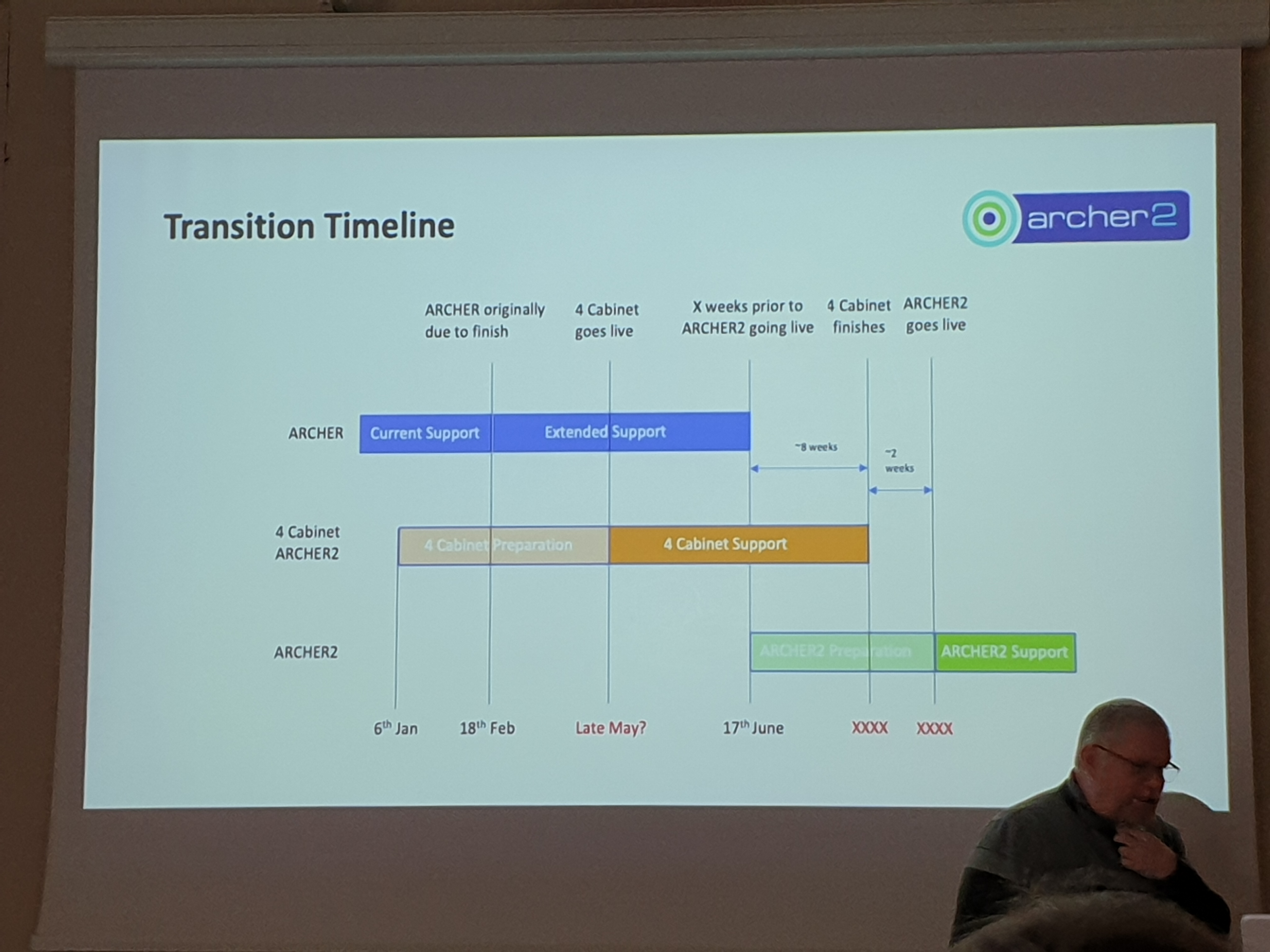
Alan Simpson (EPCC) provided the transition timeline shown in the image above. It is expected that a 4-cabinet test system will be available by mid-june and the whole system to go live around 10 weeks after. It was noted that this is an optimisic timeline and there will likely be delays added to these dates.
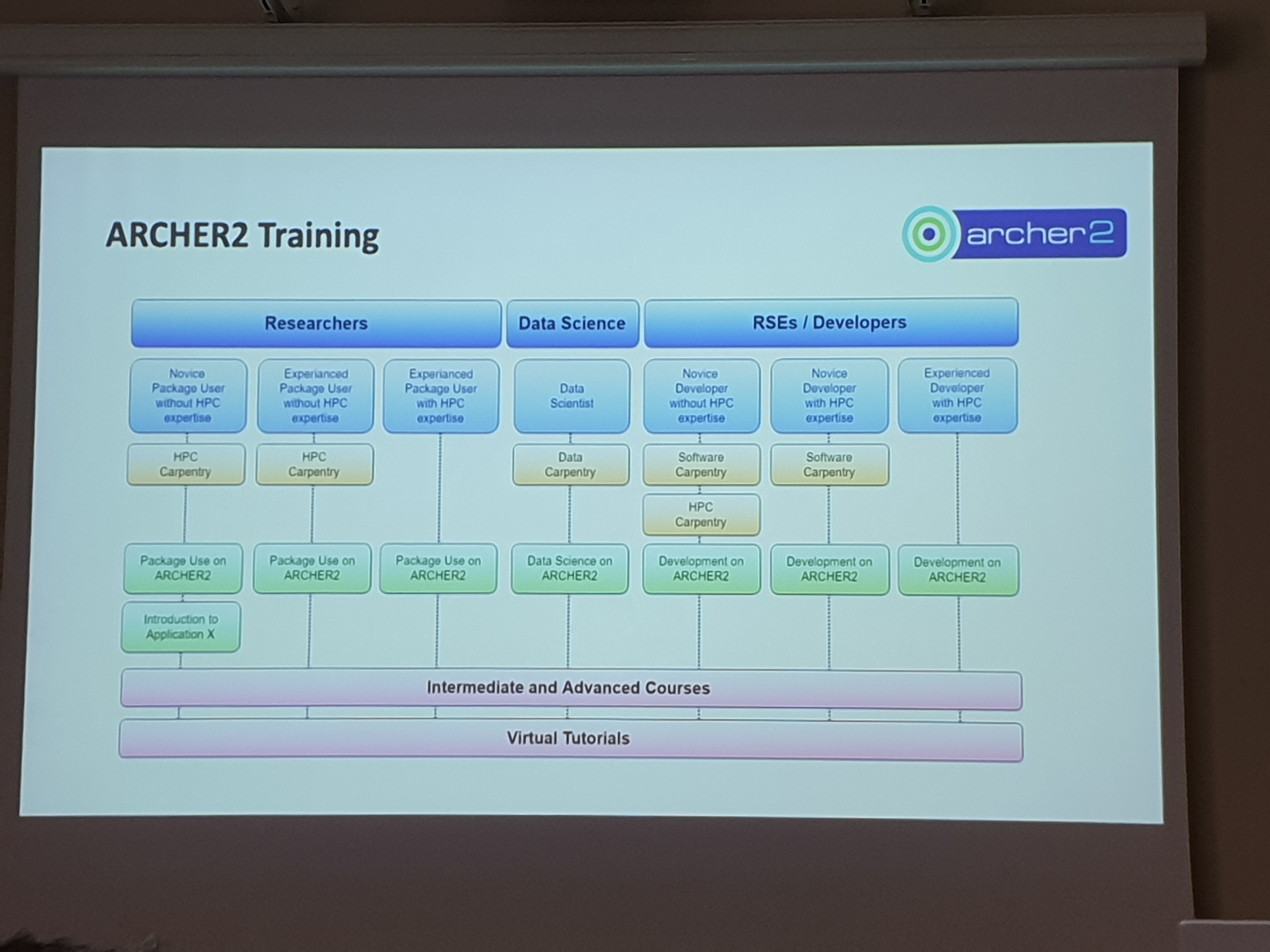
It’s also interesting to see the various training courses provided by the ARCHER team, both class based and on-line. There’s also the driving test which awards a small amount of time on the service for completing the course. I’ve been told that all of these courses are available for all researchers throughout the UK.
Tier-2 HPCs are EPSRC funded regional-level supercomputing clusters, they are designed to bridge the computational power requirement gap between national services (e.g. Archer, Tier-1) and local university HPCs (Tier-3). They are also testbeds for new and heterogeneous HPC technologies, many geared to solve particular types of algorithm or scientific problem.
If you’re in an institution that’s associated with these systems and are doing research inline with the stated purpose of system then access is often free at point-of-use so get in touch with your local Tier-2 contact to get more (and free) compute for your research! For example, if you’re doing Deep Learning or Molecular Dynamics simulation here at Sheffield you can request JADE access by filling in this JADE access form. We’re also associated with NICE and will be able to provide access once system the comes on-line.
Even if you’re not associated with one of the Tier-2 institution, it is still possible to apply for access through the EPSRC Resource Allocation Panel (RAP). Additionally, the hpc-uk website offer other ways of accessing the systems and has useful links to HPC training courses.
Funding has been approved for a refresh of the Tier-2 centres since late last year and for this round we have an addition of two centres, NICE (N8) and Kelvin-2 (Queens Belfast & Ulster). All of these new systems and refresh are mostly expected to come on-line around end of June.
More information on each of the Tier-2 centres and their updates can be found below:
Cirrus is run by EPCC in Edinburgh. The facility is based around a 280 node HPE/SGI 8600 HPC system with a DDN Lustre file system.
They’ve announced an expansion of 26 GPU nodes, each with 4 Nvidia V100 GPU connected by 8 EDR infiniband switches. The system is expected to come on-line in the first half of this year and will be used to off-load work from ARCHER during the transition.
CSD3 is run by Cambridge with STFC DiRAC and STFC IRIS as partners. The facility has 1152 32-core Intel Skylake + Intel Omnipath and 324 64-core Intel Knights landing with 360 Nvidia Pascal GPU.
With UK Atomic Energy Authority as an additional partner, the upgrade will include 672 56-core Intel Cascade Lake and 480 Nvidia’s next generation GPU (model to be announced), all using Mellanox HDR interconnects.
Isambard is run by GW4, a partnership between Bath, Bristol, Cardiff and Exeter. The system has 10,752 ARMv8 cores (Marvell thunderX2 32-cores) and a Cray XC50 ‘Scout’ system with Aries interconnect.
Isambard’s upgrade is scheduled to happen over three phases which will add a variety of hardware platforms allowing it to be used as the benchmark HPC system. The list includes 336 ARM nodes (21,504 cores), 72 Cray CS500 Fujitsu A64fx nodes, and 4 nodes each of latest CPUs and GPUs which will be continually refreshed over 2020-2021.
JADE is run by a partnership between Oxford, Alan Turing Institute, Bristol, Edinburgh, King’s College, Queen Mary, Sheffield, Southampton and UCL. It consists of 22 Nvidia DGX-1 nodes, each equipped with 8 Nvidia V100 GPUs. The system was designed primarily for Deep Learning and Molecular Dynamics simulation.
Although exact specs cannot be shared yet, the refresh will use a more power-efficient system while doubling the GPU compute power.
The Kevin-2 is an addition to the Tier-2 listing and will be the first Tier-2 cluster to serve Northern Ireland. It is run in partnership between Queen’s University Belfast and Ulster University.
The system will have 8000+ cores (dual 7702 64-core AMD CPus) with 32 Nvidia V100 GPUs.
The N8 Research Partnership is a collaboration of the eight most research intensive Universities in the North of England: Durham, Lancaster, Leeds, Liverpool, Manchester, Newcastle, Sheffield and York. They’ve won a 3.1m EPSRC grant to create the new NICE Tier-2 centre. The system will comprise 32 IBM Power 9 dual-CPU nodes, each with 4 NVIDIA V100 GPUs and high performance interconnect. An additional 6 nodes will use T4 and FPGA technology targeted towards AI inference.
Thomas is run by the Materials and Molecular Modelling Hub (MMM Hub), a partnership between Imperial College, King’s College, Queen Mary, UCL, Kent, Oxford, Queens’s University Belfast and Southampton. It has 17,280 cores (720 Lenovo Intel Broadwell nodes).
The updated system will include 23,040 cores of Xeon Cascade Lake, with 3x1.5TB and 3x3TB high memory nodes.
HPC Champions wrapped up with discussions on various Tier-2 and general HPC related topics. These include key performance indicators, whether it should be judged by the metric of number of papers generated or impact of papers. Training and on-boarding of HPC users, how there should be a form of standardisation of course materials/curriculum between the different centres and how they can collaborate together to generate this. The silo of technical instructions and issues behind private ticketing systems and how this can be opened up, possibly through sharing on open platforms such as stack exchange. Packaging of HPC software, how the users can be allowed flexibility to install their own software using package managers such as conda, Spack or EasyBuild and how the centres should also give support in building software optimised for their own cluster.
It’s definitely an eventful year for UK HPC with all of the refreshes happening. It’s great to see the variety of CPU platforms, with just about half of the centres opting for AMD, ARM or POWER chipsets as their main offering. There’s also a big investment in GPU enabled nodes as Deep Learning is being adopted into more research workflows.
That’s all from the HPC-SIG and HPC Champions this time, thank you for reading. If you have HPC problems you’re struggling with, reach out to the hpc@sheffiled.ac.uk google group. We at the RSE also run fortnightly Code Clinic sessions to help with HPC or other general technical problems in your research.
For queries relating to collaborating with the RSE team on projects: rse@sheffield.ac.uk
Information and access to Bede.
Join our mailing list so as to be notified when we advertise talks and workshops by subscribing to this Google Group.
Queries regarding free research computing support/guidance should be raised via our Code clinic or directed to the University IT helpdesk.
List of archived pages: Archive.