Members of the University of Sheffield have access to a range of GPU resources for carrying out their research, available in local (Tier 3) and affiliated regional (Tier 2) HPC systems.
As of the 7th of August 2023, 12 new H100 PCIe GPUs (6 nodes, 2 GPUs per node) have been added to the Stanage Tier 3 HPC facility and are available for all users.
At the time of writing, the following GPUs are available for members of the university, free at the point of use:
The newly available H100 GPUs in Stanage are the 300W PCIe variant, this means that for some workloads the university’s 500W A100 SXM4 GPUs may offer higher performance (with higher power consumption). For example, multi-GPU workloads which perform a large volume of GPU to GPU communication may be better suited to the A100 nodes than the H100 nodes. The new H100 nodes in Stanage each contain 2 GPUs which are only connected via PCIe to the host. The existing A100 nodes each contain 4 GPUs which are directly connected to one another via NVLink and are connected to the host via PCIe. The NVLink interconnect offers higher memory bandwidth for GPU to GPU communication, which combined with twice as many GPUs per node may lead to shorter application run-times than offered by the H100 nodes. If even more GPUs are required moving to the Tier 2 systems may be required, with Jade 2 offering up to 8 GPUs per Job, and Bede being the only current option for multi-node GPU jobs, with up to 128 GPUs per job.
Within Stanage, software may need recompiling to run on the H100 nodes, or new versions of libraries may be required. For more information see the HPC Documentation.
Carl Kennedy and Nicholas Musembi of the Research and Innovation Team in IT Services have benchmarked these new GPUs using popular machine learning frameworks, however not all HPC workloads exhibit the same performance characteristics as machine learning.
![]()
FLAME GPU 2 is an open-source GPU accelerated simulator for domain independent complex systems simulations using an agent-based modelling approach. Models are implemented using CUDA C++ or Python 3, with modellers describing the behaviours of individuals within the simulation and how they interact with one another through message lists. From these relatively simple agent behaviours and interactions, complex behaviours can emerge and be observed. The underlying use of GPUs allows for much larger scale Agent Based Simulations than traditional CPU-based frameworks with high levels of performance, while abstracting the complexities of GPU programming away from the modeller. A recent NVIDIA blog post showed how, in certain scenarios, FLAME GPU is able to operate thousands of times faster than CPU alternatives.
The default BruteForce communication pattern in FLAME GPU 2 provides global communication, with all agents reading all messages in the message list.
At large scales, this can be very costly and inefficient, so FLAME GPU 2 includes a number of specialised communication patterns to improve work-efficiency and performance where appropriate.
Spatial3D messaging is one of the available specialisations, which associates each message with a location in 3D space, and agents will only read messages from within a certain radius of their position, reducing the number of messages they read.
FLAME GPU 2 also supports two methods of compilation / optimisation for agent functions. When using the CUDA C++ interface, agent functions can be compiled off-line by NVCC like a typical CUDA / C++ program. However, as the FLAME GPU 2 API allows model details to be defined at runtime, it is possible to generate more efficient code at run-time via Run-Time Compilation (RTC), which also enables writing agent functions in (a subset) of python 3. RTC does add a one-time cost per agent function when executing the simulation for the first time, but long-running or repeated simulations amortize this cost.
A more in-depth look at the design and use of FLAME GPU 2, with NVIDIA V100 and CUDA 11.0 benchmarking of a number of features is provided by our recent publication:
Richmond, P, Chisholm, R, Heywood, P, Chimeh, MK, Leach, M. “FLAME GPU 2: A framework for flexible and performant agent based simulation on GPUs”. Softw: Pract Exper. 2023; 53(8): 1659–1680. doi: 10.1002/spe.3207
To understand how FLAME GPU 2 performs across the range of GPUs available at the University, and to further guide the development of FLAME GPU 2, we have re-benchmarked the “circles” model across the GPUs available in Stanage and Bessemer.
The FLAME GPU 2 Circles model is a force-based particle model, where each particle (agent) has a position in 3D space. The position is updated each time step by a “force” acting on the particle from other nearby particles. The closer the particles, the greater the force they exert on each other.
With random (uniform) initialisation of particles, the observed emergent behaviour of the model is that the particles will gradually form spheres over time, the scale of which depend on model parameters, as shown in the following figure.
A more thorough description of the model is provided in Section 4.1 of “FLAME GPU 2: A framework for flexible and performant agent based simulation on GPUs”.
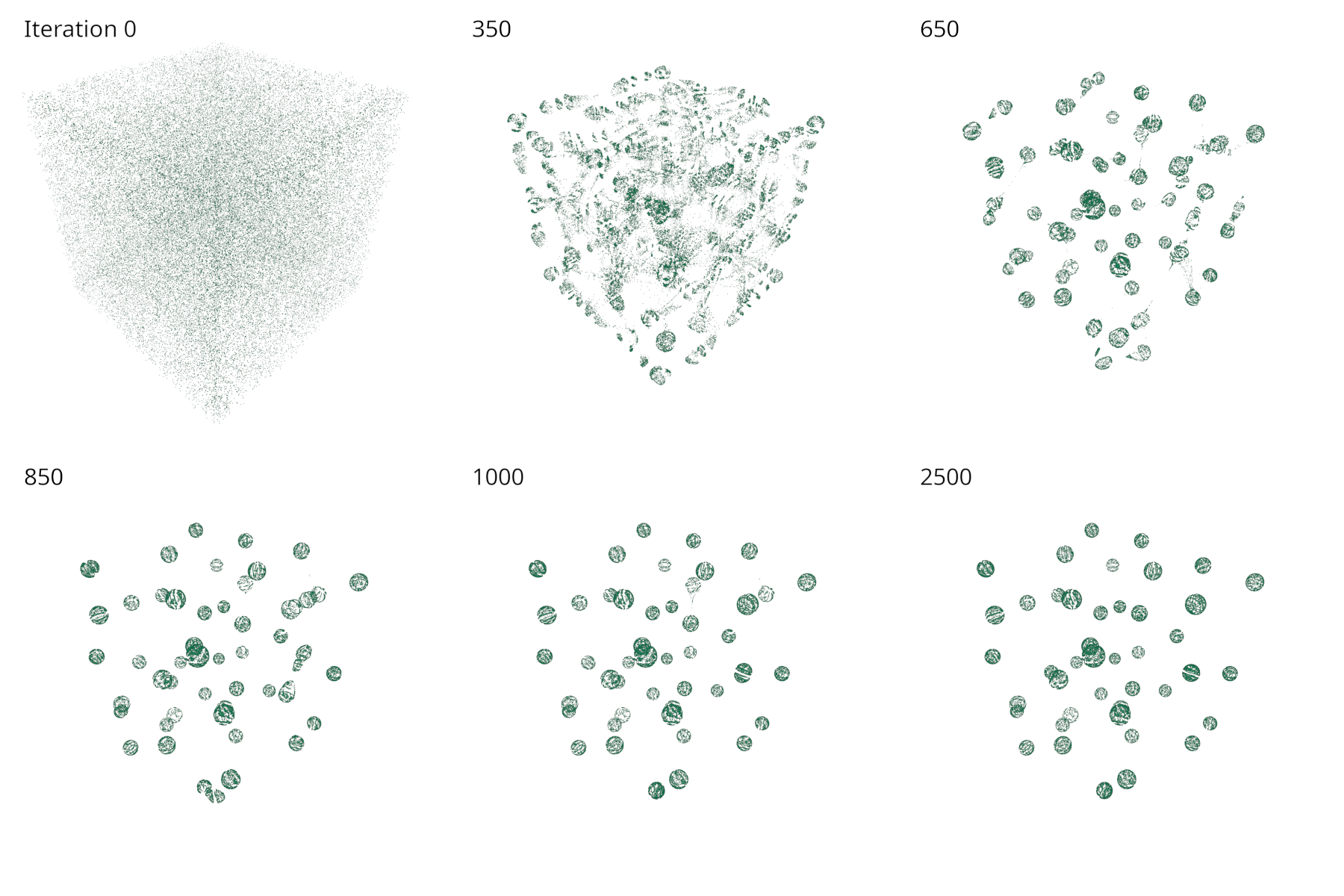
The circles-benchmark binary runs multiple benchmark experiments to evaluate the performance under different conditions.
For this blog post, we are only interested in the fixed-density benchmark, which initialises the simulation with randomly positioned circles agents, with a fixed initial density as the size of the simulated environment is scaled.
The benchmark configuration runs simulations of with 10648 to 1000000 agents.
4 Versions of the circles model were included, varying the communication strategy (BruteForce, Spatial3D) and optimisation/compilation method (non-RTC, RTC).
Each simulation was executed for 200 time steps, and was repeated 3 times to produce mean simulation execution times.
Source code for the FLAME GPU 2 Circles benchmark can be found in the FLAMEGPU/FLAMEGPU2-circles-benchmark GitHub repository.
Benchmark data was generated using FLAME GPU 2.0.0-rc, with the v2.0.0-rc tag of the circles repository.
CUDA 11.8 was used for all GPUs (via Apptainer for the V100s in Bessemer) with CMake configured for the appropriate CUDA Compute Capabilities.
FLAMEGPU_SEATBELTS, which provides better error messages and bounds checking, was disabled in the interest of performance.
All benchmarks were performed using a single GPU.
| GPU | CPU | CUDA | CMAKE_CUDA_ARCHITECTURES | FLAMEGPU_SEATBELTS |
|---|---|---|---|---|
| H100 PCIe 80G | AMD EPYC 7413 | 11.8 | 80;90 |
OFF |
| A100 SXM4 80G | AMD EPYC 7413 | 11.8 | 80;90 |
OFF |
| V100 SXM2 32G | Intel Xeon Gold 6138 | 11.8 | 70 |
OFF |
For example, the FLAMEGPU2-circles-benchmark repository can be cloned, configured and compiled for A100 and H100 GPUs via:
# Clone the benchmark repository and cd into it
git clone git@github.com:FLAMEGPU/FLAMEGPU2-circles-benchmark
cd FLAMEGPU2-circles-benchmark
# Create a build directory
mkdir -p build && cd build
# Configure CMake
cmake .. -DCMAKE_CUDA_ARCHITECTURES="80;90" -DFLAMEGPU_SEATBELTS=OFF
# Compile the binary
cmake --build . -j `nproc`
The binary was then executed within a slurm batch job (see FLAMEGPU2-circles-benchmark/scripts/slurm) containing:
# Ensure run time compilation can find the correct include directory, ideally this wouldn't be required
export FLAMEGPU2_INC_DIR=_deps/flamegpu2-src/include
# Run the benchmark experiment, outputting csv files into the working directory
./bin/Release/circles-benchmark
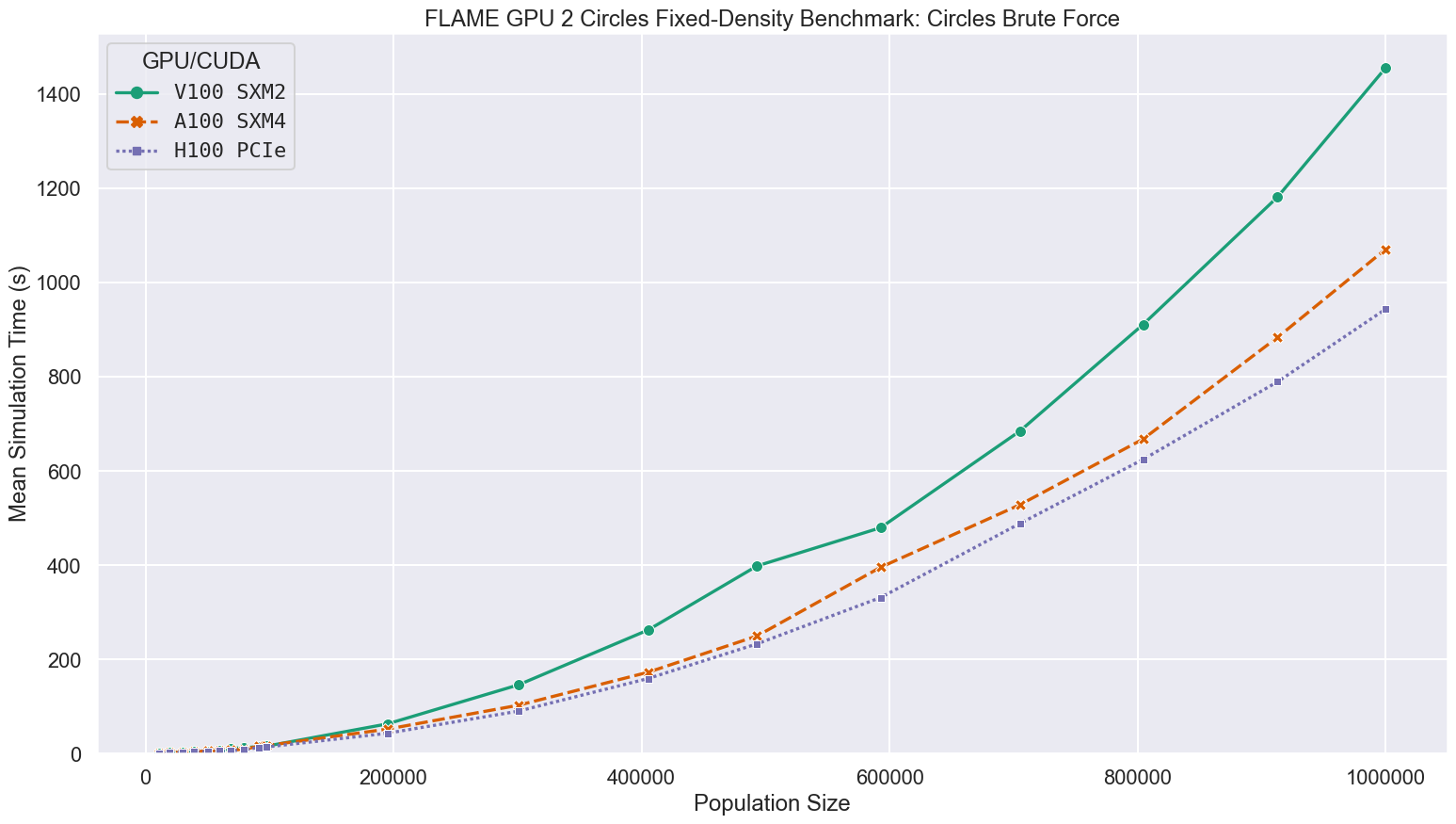
Brute Force communication is the slower of the two communication patterns used for the 3D circles model, which only needs local interaction. As each agent reads each message, complexity is quadratic with respect to the population size, and the most time consuming agent function will be limited by memory bandwidth. Broadly speaking the newer the GPU and the higher the global memory bandwidth, the faster the simulation, with larger differences at larger scales.
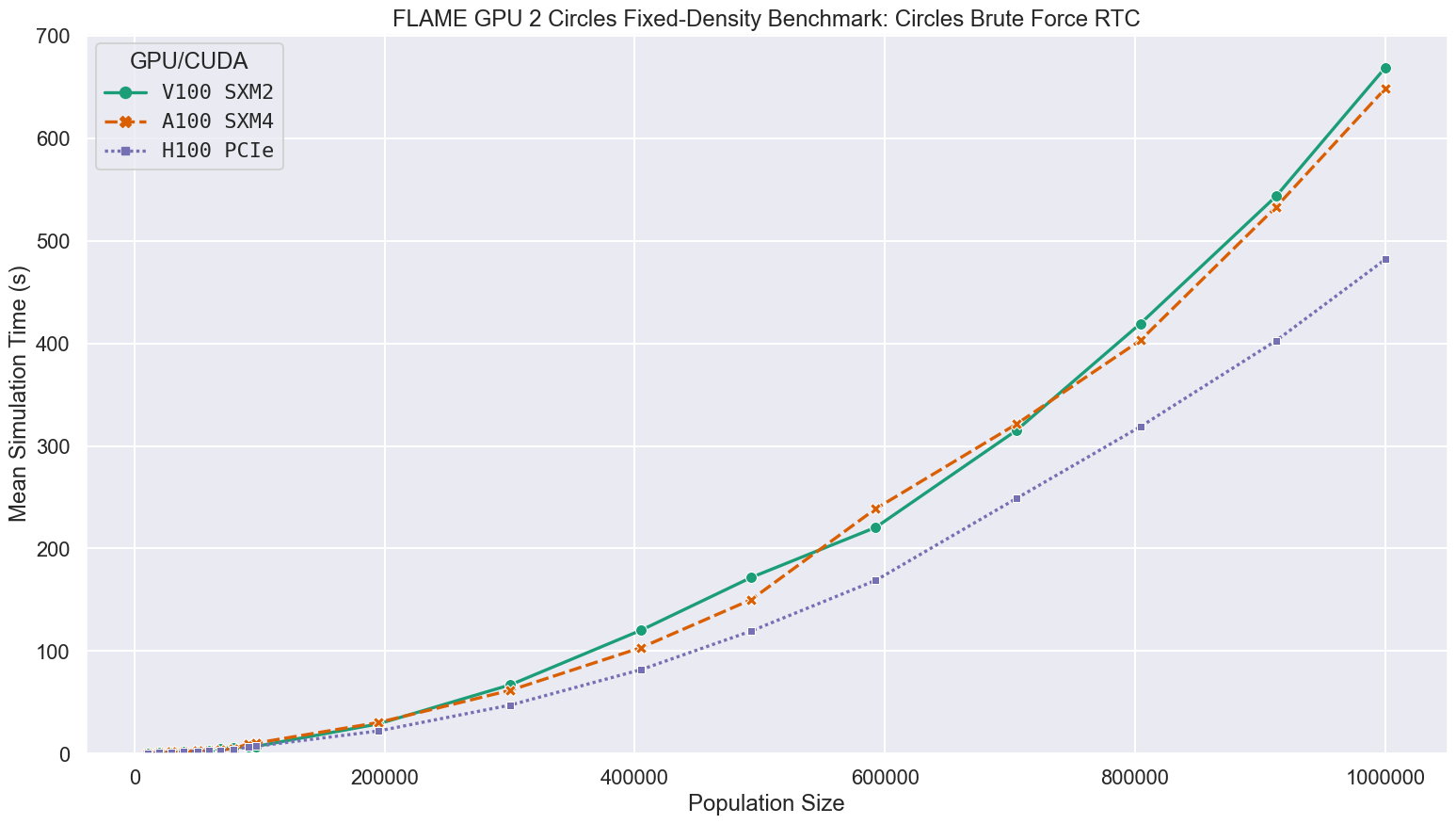
When using Run-time compilation, performance improves significantly. This is in part due to a reduction in the number of dependent global memory reads required to access agent data.
Using the much more work efficient Spatial 3D communication strategy, simulation run-times are significantly quicker than any of the brute-force benchmarks, with the largest simulations taking at most 0.944s rather than 1457s.
On average, each agent is only reading 204.5 messages, rather than all 1000000 messages each agent must read in the bruteforce case.
This greatly reduces the number of global memory reads performed and subsequently the impact of RTC is diminished although still significant.
As the initial density of the simulations and communication radius are maintained as the population is scaled, the average number of relevant messages is roughly comparable at each scale, resulting in a more linear relationship between simulation time and population size.
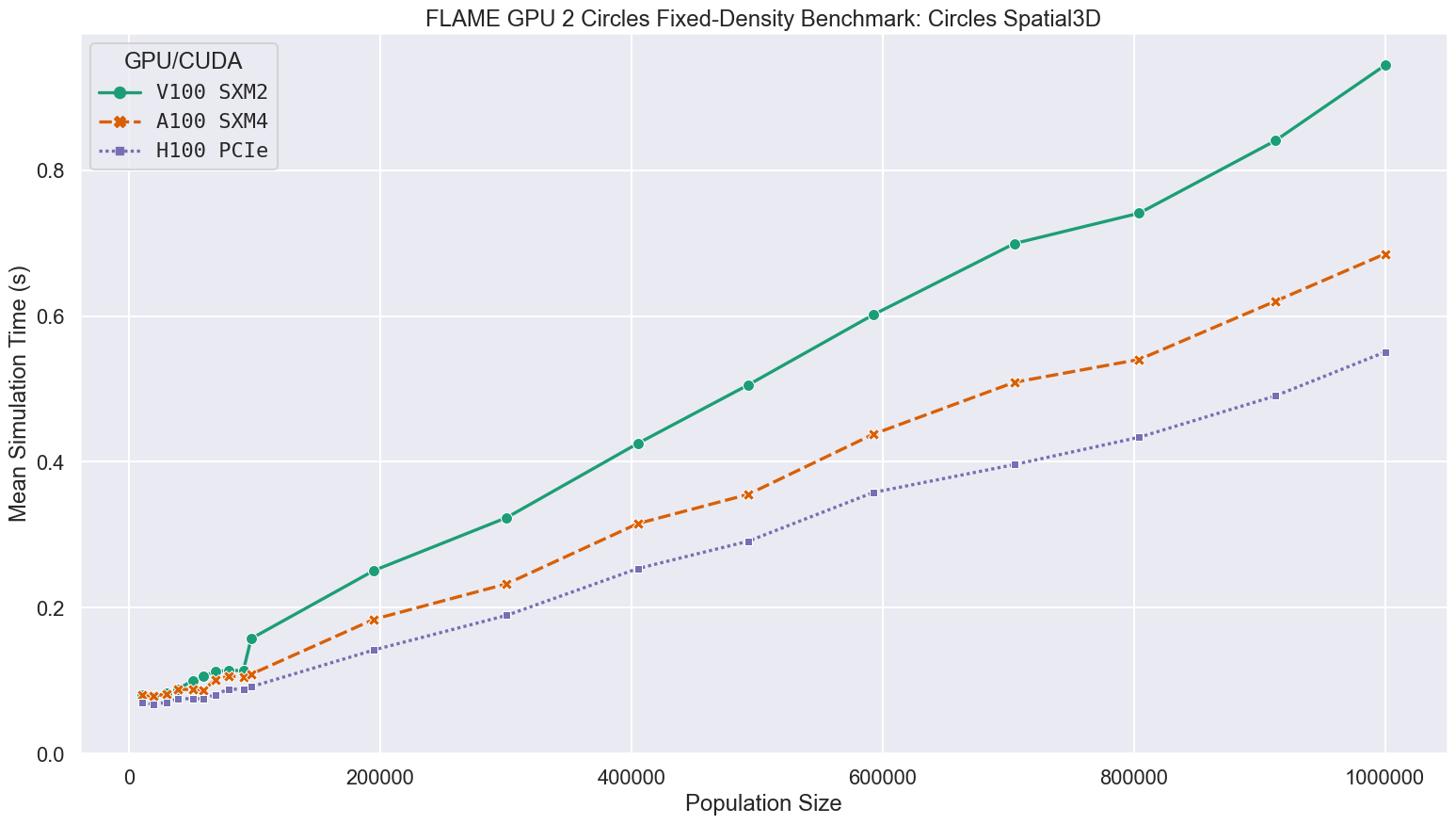
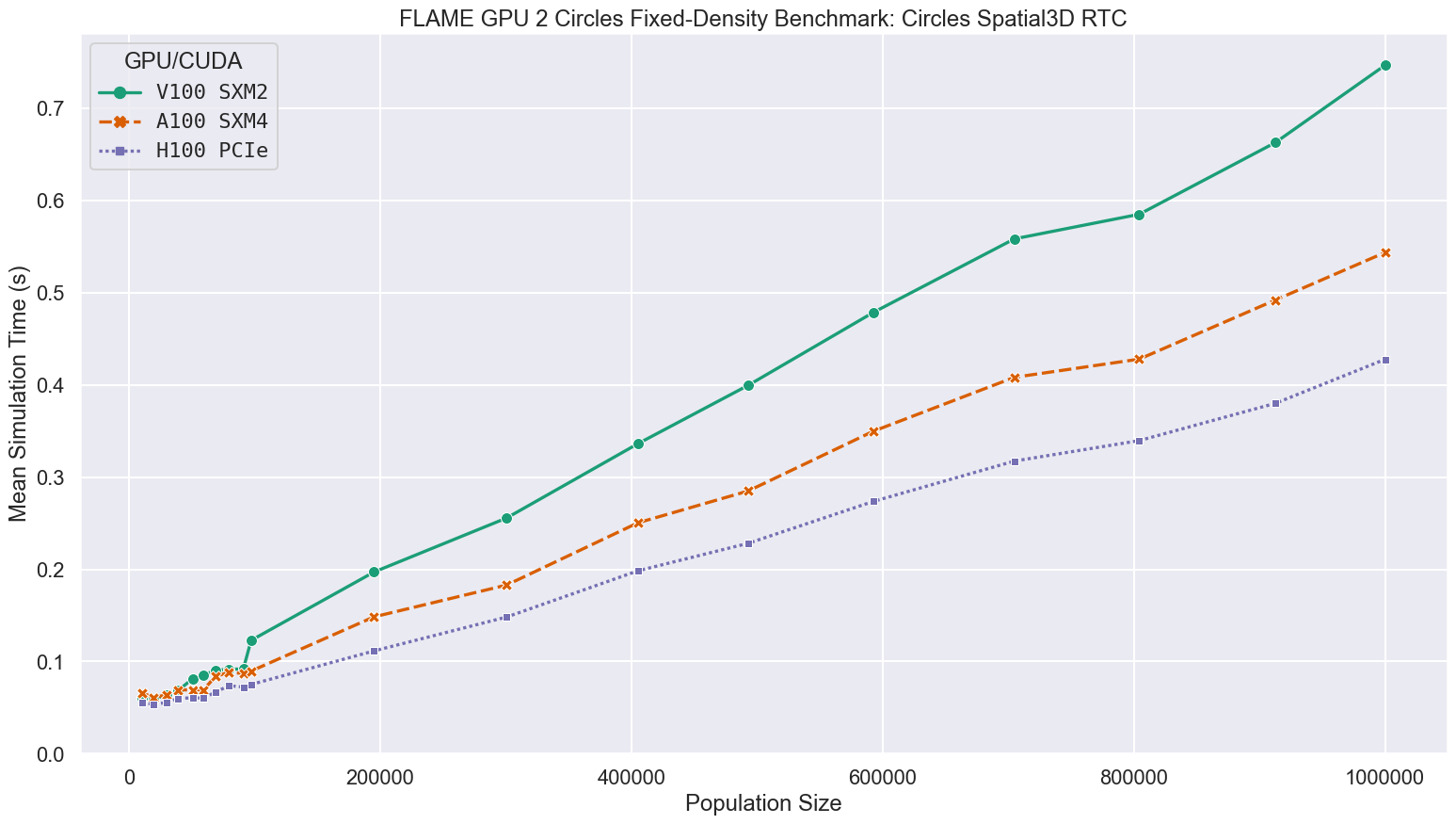
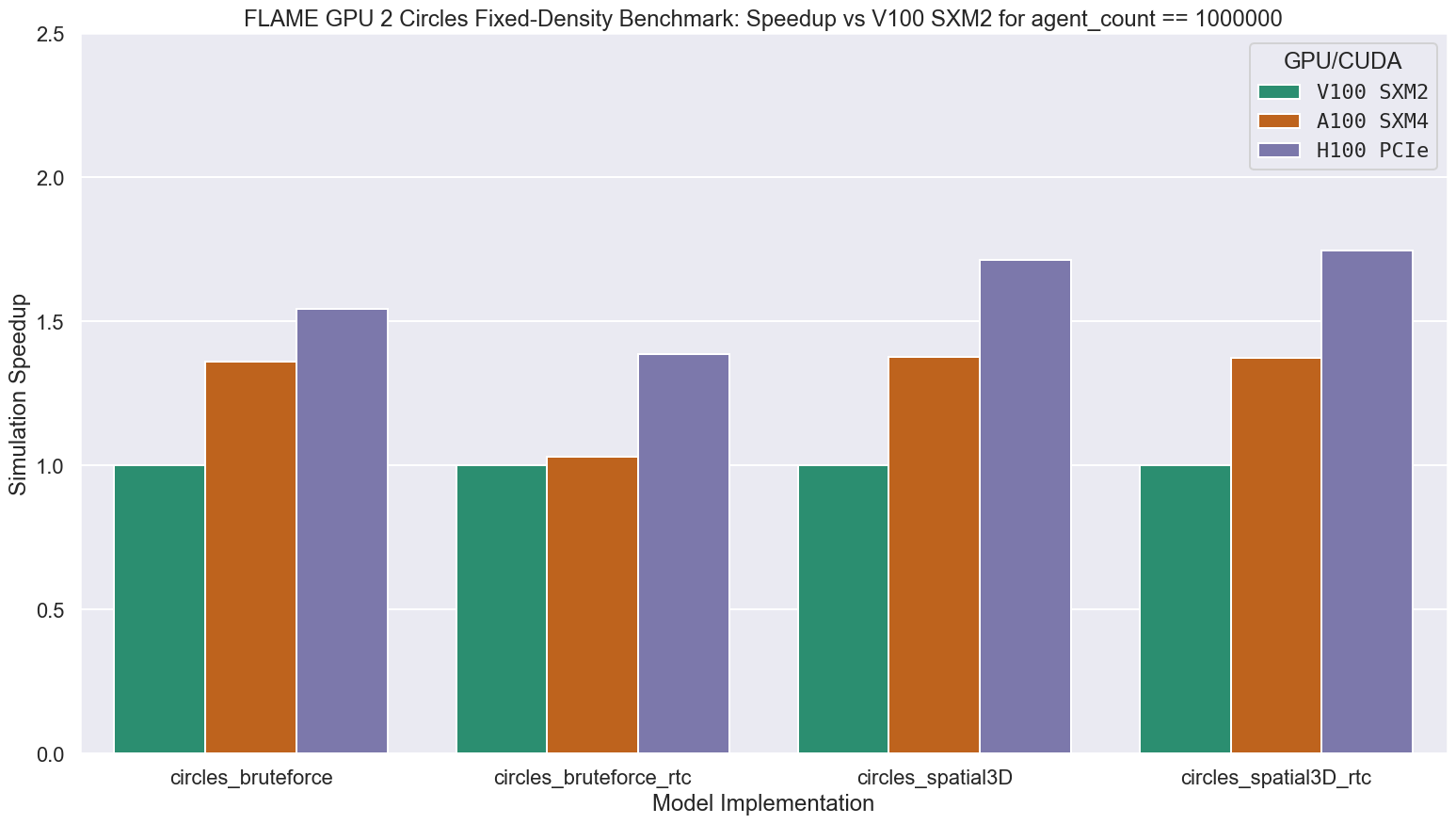
For simulations at the largest scale benchmarked, containing 1 million agents, compared to the V100 GPUs in Bessemer, the A100 and H100 GPUs in Stanage were up to 1.38 and 1.75 times faster respectively, as shown in the following figure and table.
The relative performance improvement is model and compilation method dependent.
| Benchmark | V100 SXM2 | A100 SXM4 | H100 PCIe |
|---|---|---|---|
| circles_bruteforce | 1456.716 | 1071.347 | 944.221 |
| circles_bruteforce_rtc | 668.745 | 648.341 | 481.789 |
| circles_spatial3D | 0.944 | 0.685 | 0.551 |
| circles_spatial3D_rtc | 0.747 | 0.544 | 0.428 |
| Benchmark | V100 SXM2 | A100 SXM4 | H100 PCIe |
|---|---|---|---|
| circles_bruteforce | 1.000 | 1.360 | 1.543 |
| circles_bruteforce_rtc | 1.000 | 1.031 | 1.388 |
| circles_spatial3D | 1.000 | 1.377 | 1.714 |
| circles_spatial3D_rtc | 1.000 | 1.374 | 1.746 |
Newer GPU architectures typically offer improved performance, and improved power efficiency.
Stanage, the University of Sheffield’s newest Tier 3 HPC facility now contains NVIDIA A100 SXM4 80GB and NVIDIA H100 PCIe GPUs.
Using an artificial agent based modelling benchmark (circles) implemented using FLAME GPU 2, simulations of up to 1 million individual agents were benchmarked using GPUs in Stanage and Bessemer.
Relative performance improvements of up to 1.38x and 1.75x were demonstrated using the A100 and H100 GPUs respectively compared to the V100 GPUs in Bessemer, demonstrating some of the capabilities of these newer GPUs.
For more information on the GPU resources available at the University of Sheffield, please see the HPC documentation for Stanage, Bessemer, JADE 2 & Bede. The ITS Research and Innovation Team “Machine Benchmarking A100 and H100 GPUs on Stanage” blog post provides benchmarking of some Machine Learning frameworks within Stanage.
More information on FLAME GPU 2 can be found at flamegpu.com, the FLAMEGPU/FLAMEGPU2 GitHub repository, in the FLAME GPU 2 documentation and in our recent publication “FLAME GPU 2: A framework for flexible and performant agent based simulation on GPUs”.
The benchmark model, raw data and plotting scripts can be found in the FLAMEGPU/FLAMEGPU2-circles-benchmark GitHub repository.
If you have any questions regarding FLAME GPU 2, feel free to open a discussion topic on GitHub or contact us.
For queries relating to collaborating with the RSE team on projects: rse@sheffield.ac.uk
Information and access to Bede.
Join our mailing list so as to be notified when we advertise talks and workshops by subscribing to this Google Group.
Queries regarding free research computing support/guidance should be raised via our Code clinic or directed to the University IT helpdesk.
List of archived pages: Archive.