Members of the University of Sheffield have access to a range of GPU resources for carrying out their research, available in local (Tier 3) and affiliated regional (Tier 2) HPC systems.
As of March 2024, the N8 CIR Bede Tier 2 HPC facility now includes an Open Pilot of 3 NVIDIA GH200 Nodes which are available to all users.
Each GH200 node in Bede contains a single NVIDIA GH200 Grace Hopper Superchip - a 72 core NVIDIA Grace ARM CPU connected to a single NVIDIA Hopper GPU via a 900GB/s NVIDIA NVLink-C2C interconnect. This new interconnect allows data to be moved between the host and device with a much higher bandwidth than in traditional PCI-e based systems, reducing the time spent transferring data.
The following figure shows the theoretical peak bandwidth for the range of GPU interconnect technologies used in a range of GPUs.
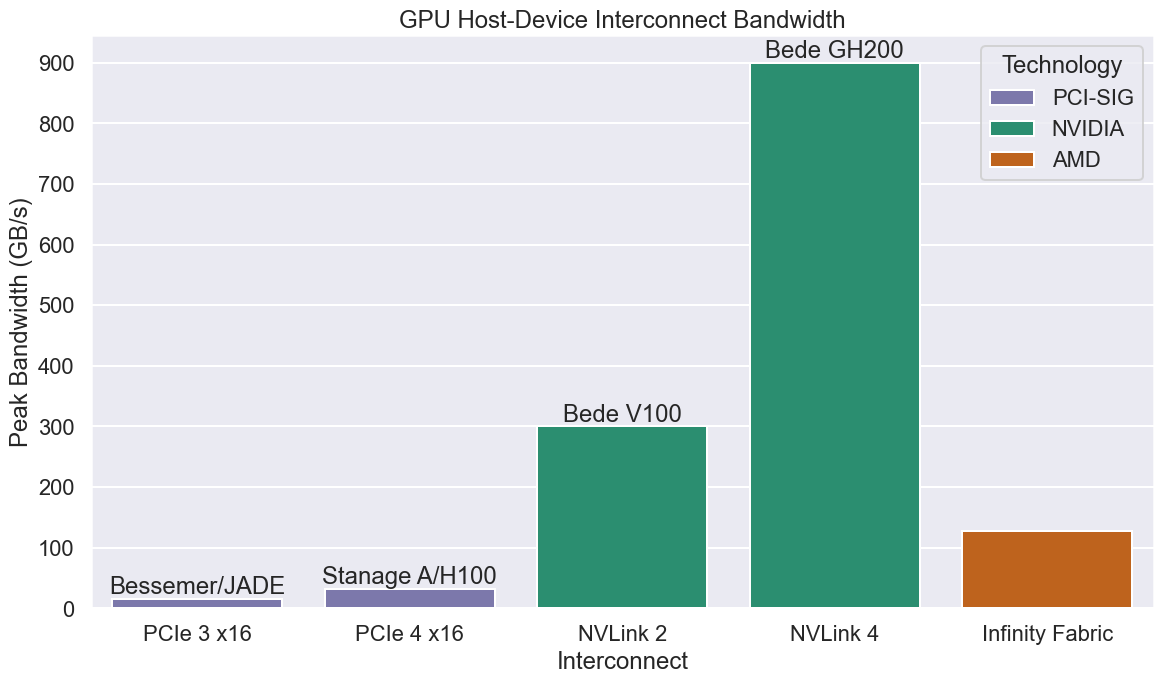 Source: github.com/ptheywood/gpu-interconnect-plots
Source: github.com/ptheywood/gpu-interconnect-plots
To illustrate the performance of the GH200 GPUs for machine learning workloads, a benchmark of LLM fine-tuning previously used by Farhad Allian (a Research Data Engineer in Research & Innovation IT) to investigate the performance of NVIDIA L40 GPUs for machine learning benchmarked on the GH200 GPUs in Bede.
The benchmark uses the HuggingFace Transformers run_clm.py example to train and evaluate the fine-tuning of the GPT-2 124 million parameter LLM using the WikiText-2 (raw) dataset in FP32 and FP16 precisions.
Each benchmark was repeated 3 times, using a single batch size of 8.
This batch size allows the benchmark to be repeated on GPUs with lower memory capacity, but larger batch sizes would likely improve performance for GPUs with sufficient memory, such as the GH200.
As of April 2024, pre-built binary wheels and conda packages for PyTorch for aarch64 systems such as the GH200 do not include CUDA support.
Instead, the benchmark was containerised via Apptainer, using containers based on the NGC PyTorch containers.
Version 24.02 was used for this benchmark, resulting in a software environment containing:
3.1012.3.22.3.0a0+ebedce24.37.0The benchmark was then executed on V100 GPUs in Bessemer, A100 & H100 PCIe GPUs in Stanage, and the GH200 GPUs in Bede. Source files, instructions, job submission scripts and the generated results and figures can be found in the RSE-Sheffield/pytorch-transformers-wikitext2-benchmark GitHub repository.
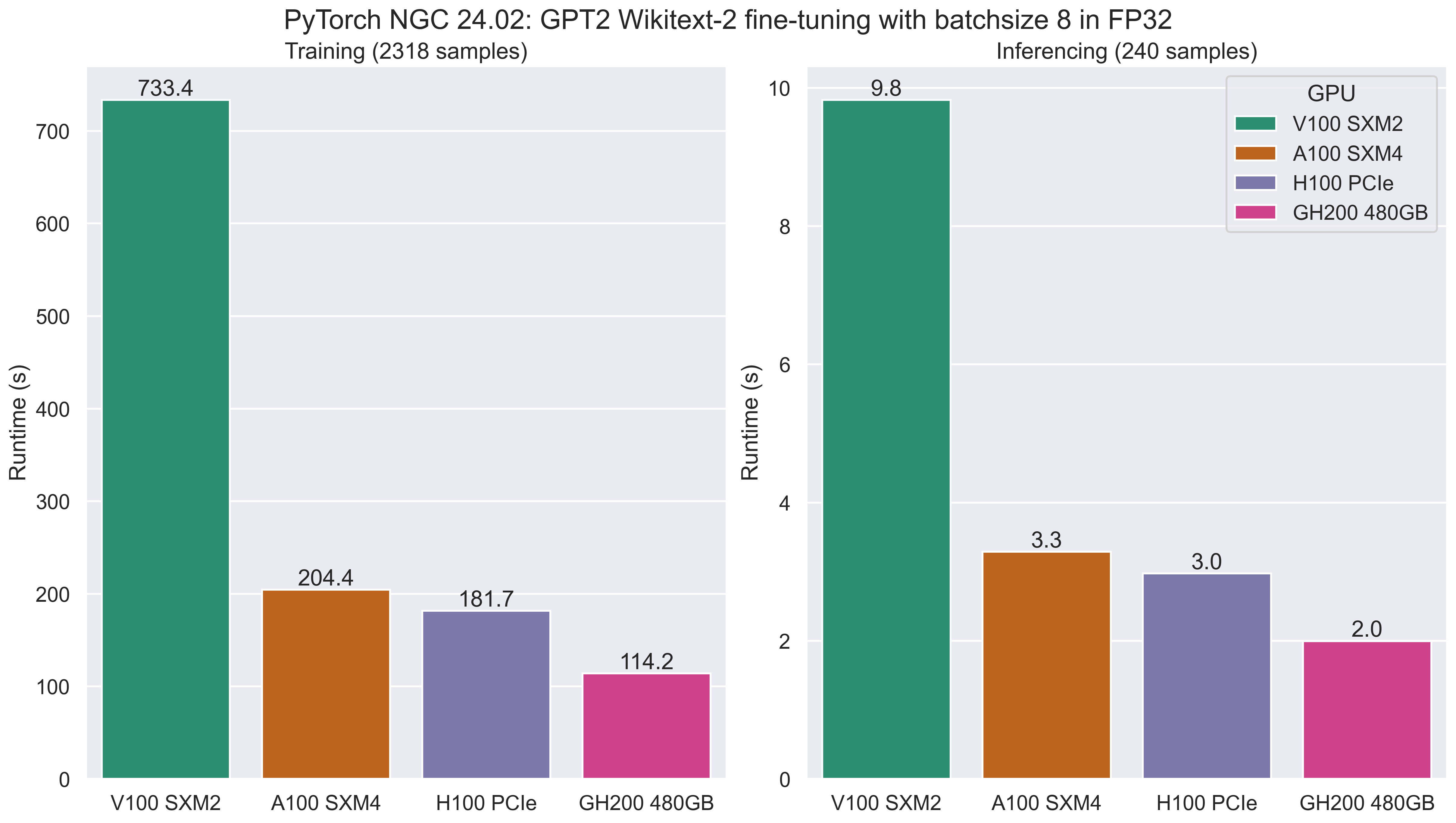
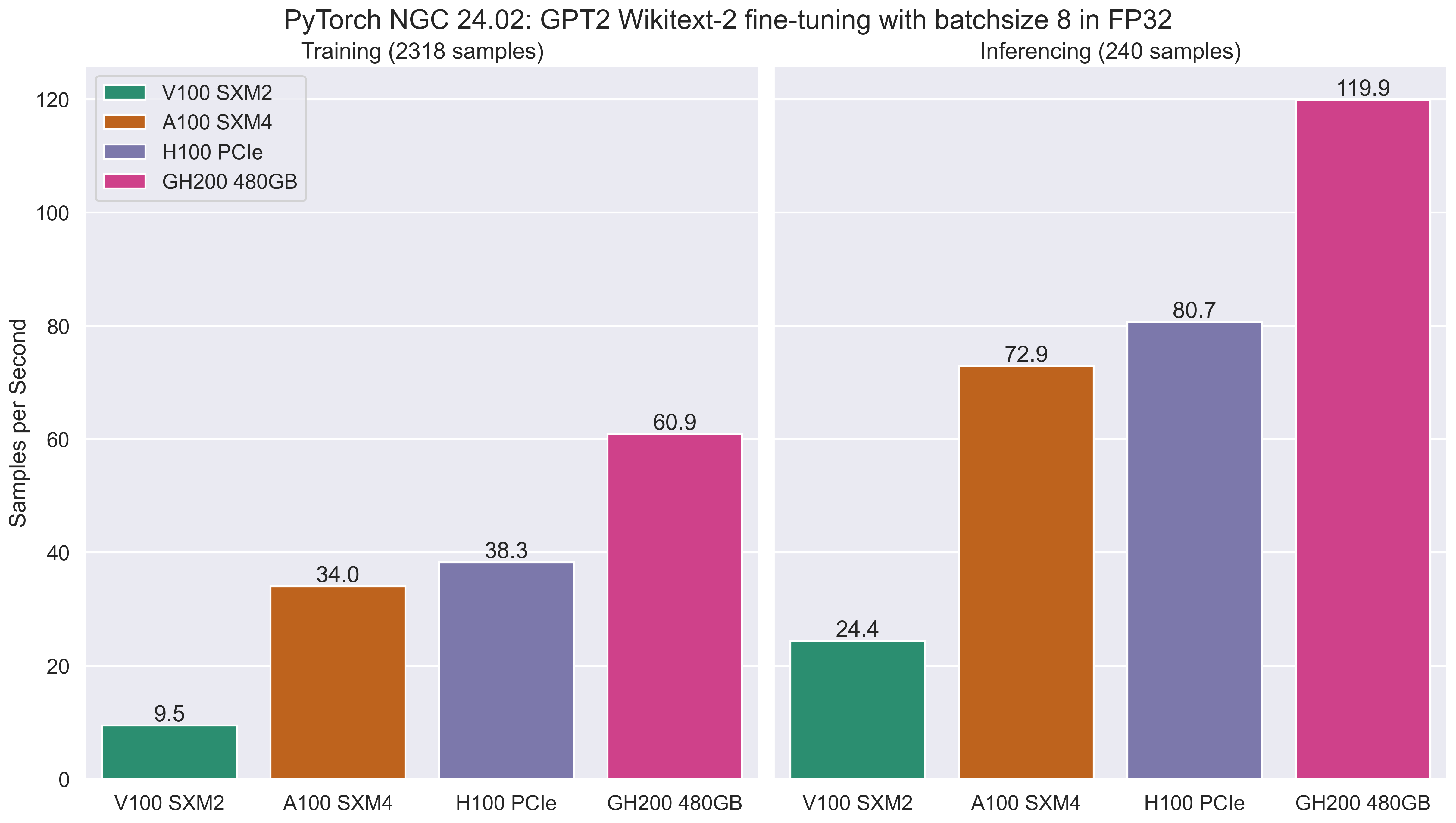
The following figures and tables show the benchmark data for FP32 training and inferencing on across a range of GPUs.
This includes the runtime training and inferencing phases in seconds (lower is better), and the samples processing rate in samples per second (higher is better).
As you might expect, newer generations of GPU offer reduced application runtimes and increased performance compared to previous generations, with the GH200 outperforming the V100 SXM2 GPUs in Bessemer, the A100 SXM4 GPUs in Stanage and the H100 PCIe GPUs in Stanage.
| Metric | V100 SXM2 | A100 SXM4 | H100 PCIe | GH200 480GB |
|---|---|---|---|---|
| FP32 Training Time (s) | 733.447 | 204.360 | 181.747 | 114.210 |
| FP32 Inference Time (s) | 9.827 | 3.287 | 2.973 | 1.997 |
| FP32 Training Samples per Second | 9.481 | 34.028 | 38.261 | 60.886 |
| FP32 Inference Samples per Second | 24.413 | 72.932 | 80.666 | 119.908 |
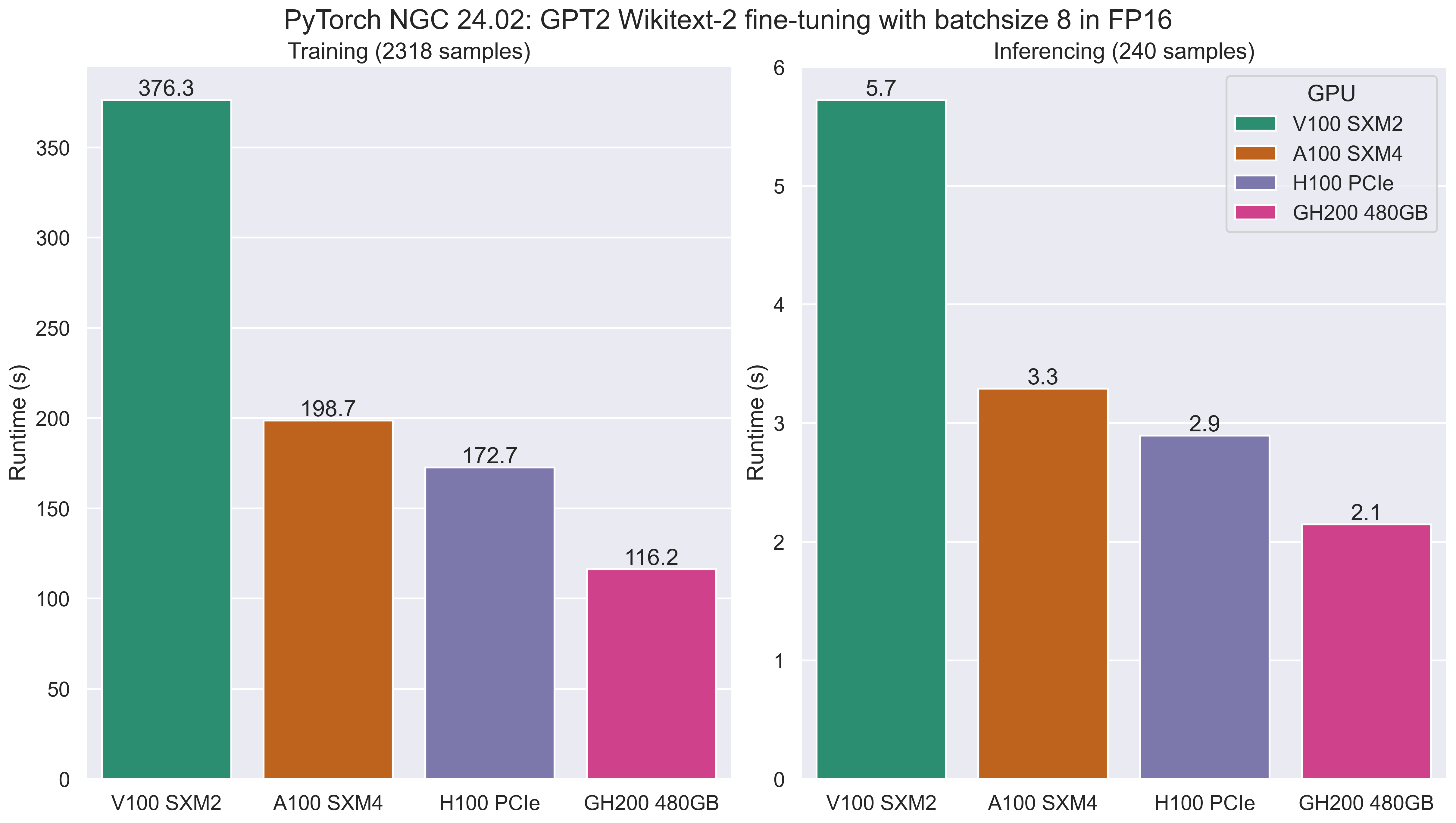
The following figures and tables show the benchmark data for FP16 training and inferencing on across a range of GPUs.
This includes the runtime training and inferencing phases in seconds (lower is better), and the samples processing rate in samples per second (higher is better).
As with the FP32 results, the newer generations of GPU offer improved performance over older GPUs, with the GH200 out-performing the other models. The relative performance difference will vary from workload to workload, with larger batch sizes likely showing increased performance.
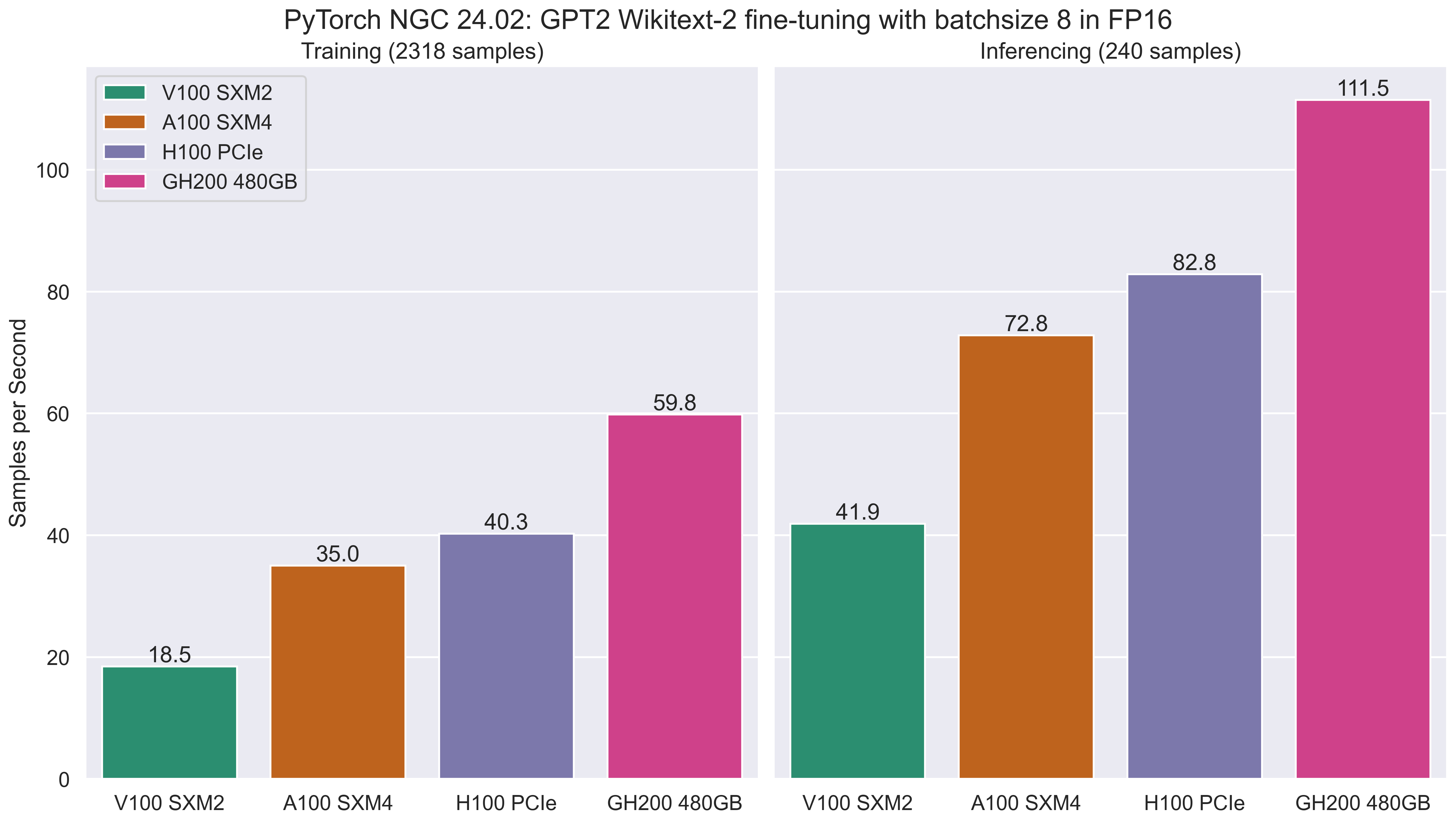
| Metric | V100 SXM2 | A100 SXM4 | H100 PCIe | GH200 480GB |
|---|---|---|---|---|
| FP16 Training Time (s) | 376.310 | 198.677 | 172.673 | 116.243 |
| FP16 Inference Time (s) | 5.723 | 3.290 | 2.893 | 2.147 |
| FP16 Training Samples per Second | 18.479 | 35.001 | 40.271 | 59.833 |
| FP16 Inference Samples per Second | 41.892 | 72.819 | 82.826 | 111.463 |
As a member organisation of the N8 CIR, Bede is available for use by an researchers at the University of Sheffield.
Access is granted on a per project basis, with the N8 CIR Bede website providing instructions on how to apply for access via the online form. Once submitted, the application will be reviewed and if deemed appropriate and compatible with Bede the project will be created.
Bede’s online documentation now includes GH200 specific information on the appropriate pages, in addition to the high level overview of the GH200 pilot. However, as there are only a limited number of GH200 GPUs in Bede at this time, jobs may spend a significant amount of time in the queue.
In addition to Bede, Sheffield researchers can also access a range of GPUs in our local Tier 3 facilities Bessemer and Stanage; as well as the Tier 2 JADE HPC Facility.
For queries relating to collaborating with the RSE team on projects: rse@sheffield.ac.uk
Information and access to Bede.
Join our mailing list so as to be notified when we advertise talks and workshops by subscribing to this Google Group.
Queries regarding free research computing support/guidance should be raised via our Code clinic or directed to the University IT helpdesk.
List of archived pages: Archive.