
The Research Software Engineering team at the University of Sheffield has gained a new member. I joined at the start of January and will primarily be working on OpenDreamKit which is a Horizon 2020 European Research Infrastructure project with the aim of furthering the open-source computational mathematics ecosystem.
My contribution to this project is to extend work previously started at the University of Sheffield to allow researchers to more easily run interactive workflows on High-Performance Computing clusters, specifically to make it easy, robust and intuitive to run Jupyter Notebooks on clusters running job scheduling software from the Grid Engine family.
Jupyter Notebooks are runnable documents containing code snippets that are viewed and manipulated from a web browser. They are an increasingly popular way of encapsulating, presenting and sharing a coding-oriented workflow. A Notebook comprises a column of cells, where each cell can contain:
When a code cell is executed by the user it can return anything renderable by a modern web browser:
For example:
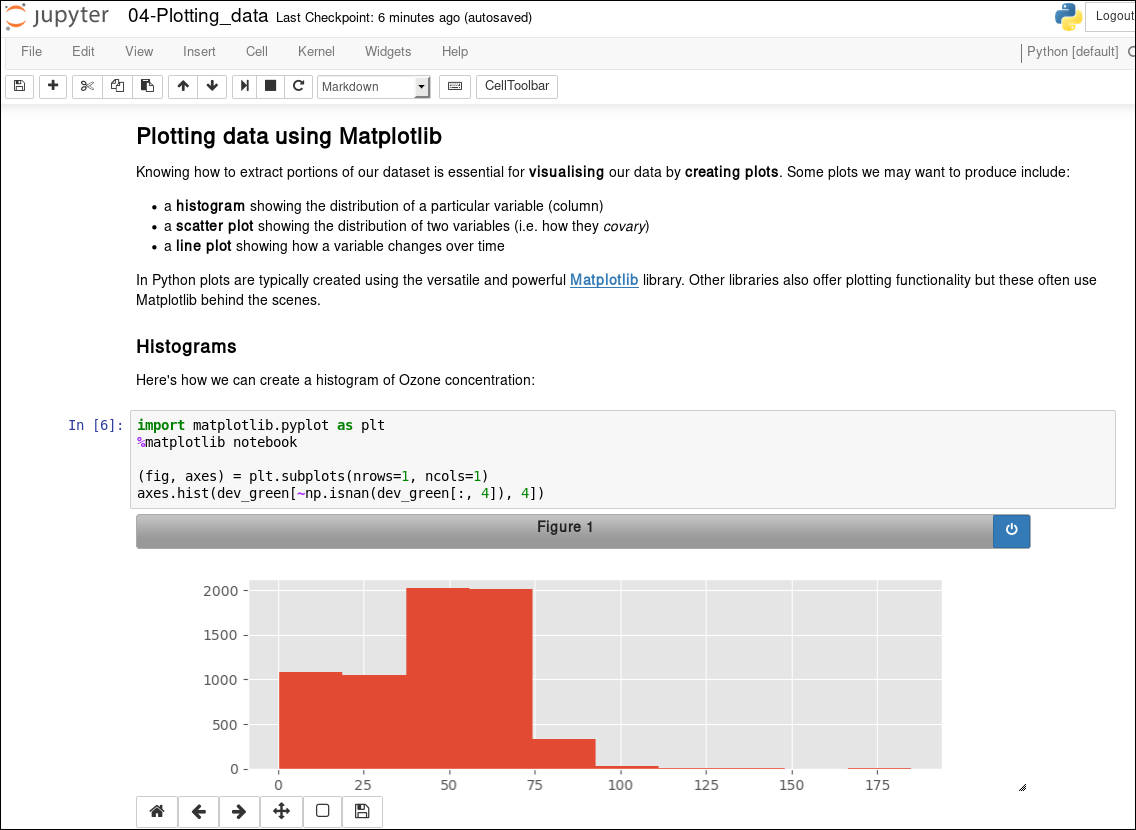
The code cells of a Notebook can be (re)run in any order, so Notebooks are very useful for interactive exploration.
The structure of Jupyter is typically as follows: :
[Notebook in browser] <---> [Jupyter server] <---> [Kernel]
where the kernel is the part that executes code cells. There are kernels for many different programming languages!
The server and kernel can run on the same machine as the web browser but the architecture allows them to also run on remote machines. These remote systems could be:
This is where my part of OpenDreamKit comes in. Computer clusters such as Iceberg and ShARC here at the University of Sheffield allow users to run computational jobs with more resources than typically available in researchers’ own machines. Jobs can have parallel threads of execution running on up to sixteen cores per node and/or running over multiple nodes, jobs can use hundreds of MB of RAM and can make use of the latest generation of GPUs for things like accelerated deep learning workflows. However, the need to request resources, then submit and monitor jobs from the command-line can be a steep barrier to entry for some. Being able to easily run Jupyter Notebooks on our clusters and request the necessary resources for our interactive explorations via an intuitive web interface could help make HPC more accessible and useful to those without a strong understanding of Linux and the command-line.
We already have an instance of JupyterHub running to allow users to start Jupyter sessions on our Iceberg cluster thanks to the efforts of Stuart Mumford. I will be working on:
I’m rather excited about this new role. One nice aspect to it is that I am now according to my contract officially a Research Software Engineer:
Dear Dr Furnass
Further to recent discussions, I am pleased to confirm the change in your appointment with the University of Sheffield. The details of your offer are provided below:
Appointment Details: You, Dr William Furnass, shall be employed by the University of Sheffield as a Research Software Engineer in the Department of Computer Science with effect from 1 January 2017. This position is offered on a fixed term basis.
This demonstrates that research institutions have started recognising Research Software Engineering as an alternative career path in academia (something the Software Sustainability Institute have been pushing for for some time) and RSEs aren’t simply post-doctoral researchers who happen to write software.
The path to this point has not been particularly direct: I have a computer scence degree, worked as a IT systems engineer in the film industry, have a PhD plus post-doc experience in water engineering (where I developed semi-physical and data-driven models of water quality in water distribution networks) and I have provided support to the users of the University of Sheffield’s HPC clusters. In addition I taught or helped run RSE, water engineering and study skills workshops.
My interests include helping researchers optimise data analysis workflows (primarily using higher-level languages), providing training in RSE best practices and systems administration. You can contact me via:
For queries relating to collaborating with the RSE team on projects: rse@sheffield.ac.uk
Information and access to Bede.
Join our mailing list so as to be notified when we advertise talks and workshops by subscribing to this Google Group.
Queries regarding free research computing support/guidance should be raised via our Code clinic or directed to the University IT helpdesk.
List of archived pages: Archive.