Getting Started with Conda
Overview
Teaching: 15 min
Exercises: 5 minQuestions
What are the key terms I need to understand such as ‘package’, ‘dependency’ and ‘environment’?
Why should I use a package and environment management system as part of my research workflow?
What is Conda and why should I use it?
Objectives
Understand why you should use a package and environment management system as part of your (data) science workflow.
Explain the benefits of using Conda as part of your (data) science workflow.
Packages and Environments
When working with a programming language, such as Python, that can do almost anything, one has to wonder how this is possible. You download Python, it is about 25 MB, how can everything be included in this small data package. The answer is - it is not. Python, as well as many other programming languages use additional software for being able to doing almost anything. You can see this already when you start programming. After learning some very basics, you often learn how to import something into your script or session.
Packages
Additional software is grouped together into packages e.g. numpy or pytorch to make it easier to
install just the bits we need. Different programming languages have different types of package, and some have
several.
A Conda package, for example,
is a compressed archive file (.tar.bz2 or .conda) that contains:
- system-level libraries
- Python or other modules
- executable programs and other components
- metadata under the
info/directory - a collection of files that are installed directly into an
installprefix.
All Conda packages have a specific sub-directory structure inside the archive file, the detail of what goes on in there is beyond the scope of this course.
Dependencies
A bit further into your programming career you may notice/have noticed that many packages do not just do everything on
their own. Instead, they depend on other packages for their functionality. For example, the scipy
package is used for numerical routines. To not reinvent the wheel, the package makes
use of other packages, such as numpy (numerical python) and matplotlib (plotting) and many more. So we say that
numpy and matplotlib are dependencies of scipy.
Many packages are being further developed all the time, generating different versions of packages. During development
it may happen that a function call changes and/or functionalities are added or removed. If one package can depend on
another, this may create issues. Therefore it is not only important to know that e.g. scipy depends on numpy and
matplotlib, but also could be that it depends on numpy version >= 1.19.5 and matplotlib version >= 2. numpy
version 1.5 in this case would not be sufficient.
Conda keeps track of the dependencies between packages and platforms.
Environments
When starting with programming we may not use many packages yet and the installation may be straightforward. But for most people, there comes a time when one version of a package or also the programming language is not enough anymore. You may find an older tool that depends on an older version of your programming language (e.g. Python 2.7), but many of your other tools depend on a newer version (e.g. Python 3.6). You could now start up another computer or virtual machine to run the other version of the programming language, but this is not very handy, since you may want to use the tools together in a workflow later on. Here, environments are one solution to the problem. Nowadays there are several environment management systems following a similar idea: Instead of having to use multiple computers or virtual machines to run different versions of the same package, you can install packages in isolated environments.
Package management
A good package management system greatly simplifies the process of installing software by…
- identifying and installing compatible versions of software and all required dependencies.
- handling the process of updating software as more recent versions become available.
If you use some flavor of Linux, then you are probably familiar with the package manager for your
Linux distribution (i.e., apt on Ubuntu, yum on CentOS); if you are a Mac OSX user then you
might be familiar with the Home Brew Project which brings a Linux-like package
management system to Mac OS; if you are a Windows OS user, then you may not be terribly familiar
with package managers as there isn’t really a standard package manager for Windows (although there
is the Chocolatey Project).
Operating system package management tools are great but these tools actually solve a more general problem than you often face as a (data) scientist. As a (data) scientist you typically use one or two core scripting languages (i.e., Python, R, SQL). Each scripting language has multiple versions that can potentially be installed and each scripting language will also have a large number of third-party packages that will need to be installed. The exact version of your core scripting language(s) and additional, third-party packages will also probably change from project to project.
Why should I use a package and environment management system?
Installing software is hard. Installing scientific software is often even more challenging. In order to minimize the burden of installing and updating software (data) scientists often install software packages that they need for their various projects system-wide.
Installing software system-wide has a number of drawbacks:
- It can be difficult to figure out what software is required for any particular research project.
- It is often impossible to install different versions of the same software package at the same time.
- Updating software required for one project can often “break” the software installed for another project.
Put differently, installing software system-wide creates complex dependencies between your research projects that shouldn’t really exist!
Rather than installing software system-wide, wouldn’t it be great if we could install software separately for each research project?
An environment management system solves a number of problems commonly encountered by (data) scientists.
- An application you need for a research project requires different versions of your base programming language or different versions of various third-party packages from the versions that you are currently using.
- An application you developed as part of a previous research project that worked fine on your system six months ago now no longer works.
- Code that was written for a joint research project works on your machine but not on your collaborators’ machines.
- An application that you are developing on your local machine doesn’t provide the same results when run on your remote cluster.
graph TD;
subgraph C1["Bob's Computer"]
birdcore["
'Birdcore' Environment
Python 3.6
Pandas 1.0.1
PySpark 2.4.8
"]
spaceship1["
'Spaceship' Environment
Python 3.10
Pandas 1.3.5
Matplotlib 3.5.1"]
end
subgraph C2["Fariba's Computer"]
fishstick["
'Fishstick' Environment
Python 2.7
Numpy 1.14.4
Matplotlib 2.2.5
"]
spaceship2["
'Spaceship' Environment
Python 3.10
Pandas 1.3.5
Matplotlib 3.5.1"]
end
birdcore --> run_spaceship_a["Run Spaceship.py ❌"]
spaceship1 --> run_spaceship_b["Run Spaceship.py ✔️"]
fishstick --> run_spaceship_c["Run Spaceship.py ❌"]
spaceship2 --> run_spaceship_d["Run Spaceship.py ✔️"]
An environment management system enables you to set up a new, project specific software environment containing specific Python versions as well as the versions of additional packages and required dependencies that are all mutually compatible.
- Environment management systems help resolve dependency issues by allowing you to use different versions of a package for different projects.
- Make your projects self-contained and reproducible by capturing all package dependencies in a single requirements file.
- Allow you to install packages on a host on which you do not have admin privileges.
Conda
From the official Conda documentation. Conda is an open source package and environment management system that runs on Windows, Mac OS and Linux.
- Conda can quickly install, run, and update packages and their dependencies.
- Conda can create, save, load, and switch between project specific software environments on your local computer.
- Although Conda was created for Python programs, Conda can package and distribute software for any language such as R, Ruby, Lua, Scala, Java, JavaScript, C, C++, FORTRAN.
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because Conda is also an environment manager. With just a few commands, you can set up a totally separate environment to run that different version of Python, while continuing to run your usual version of Python in your normal environment.
Conda vs. Miniconda vs. Anaconda
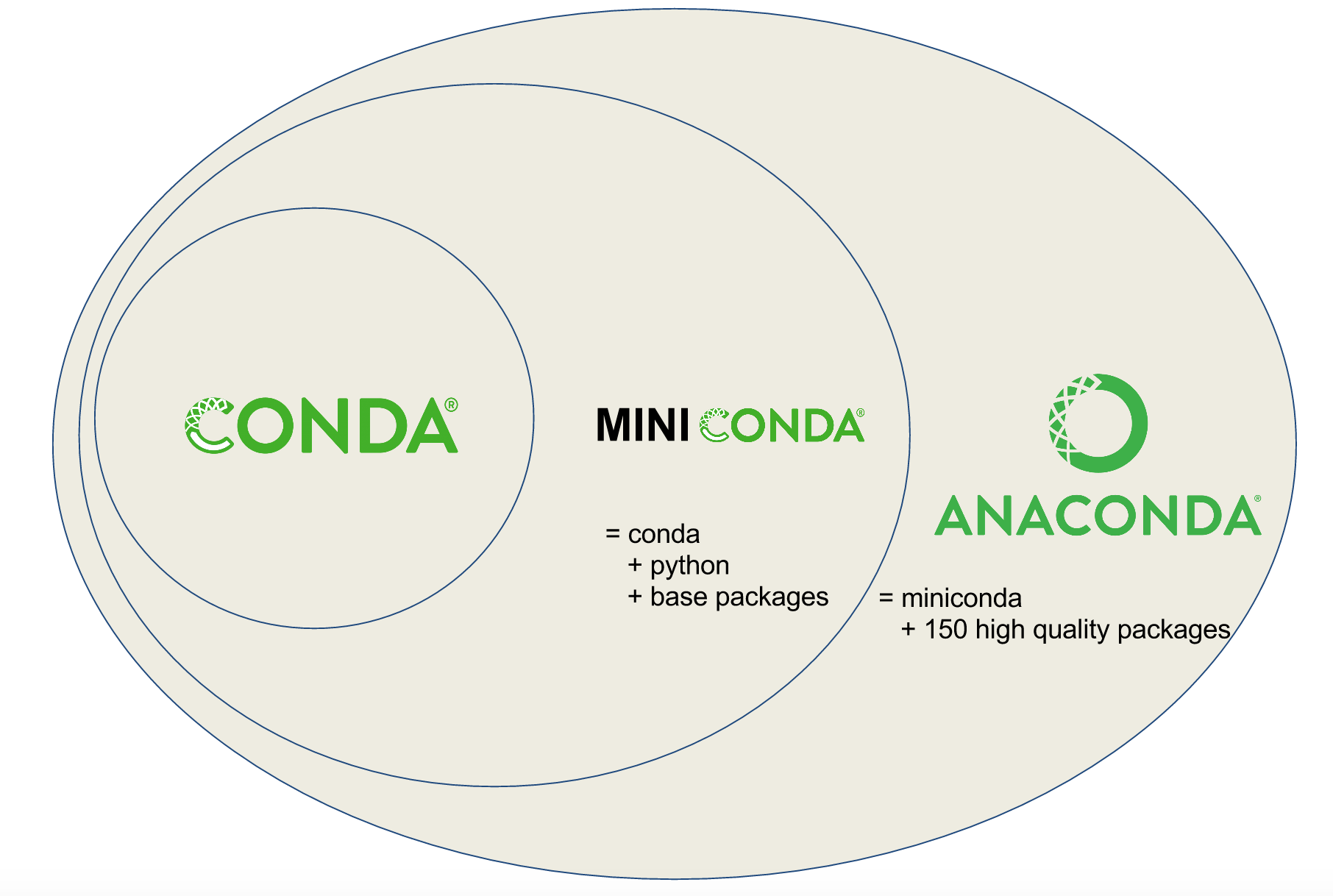
Users are often confused about the differences between Conda, Miniconda, and Anaconda. Conda is a tool for managing environments and installing packages. Miniconda combines Conda with Python and a small number of core packages; Anaconda includes Miniconda as well as a large number of the most widely used Python packages.
Why use Conda?
In Python there is a built in package manager pip and virtual environment manager venv, so
why use Conda? Whilst there are many different package and environment management systems that solve either the
package management problem or the environment management problem, Conda solves both of these
problems and is explicitly targeted at (data) science use cases.
- Conda provides prebuilt packages, avoiding the need to deal with compilers, or trying to work out how exactly to set up a specific tool. Fields such as Astronomy use conda to distribute some of their most difficult-to-install tools such as IRAF. TensorFlow is another tool where to install it from source is near impossible, but Conda makes this a single step.
- Conda is cross platform, with support for Windows, MacOS, GNU/Linux, and support for multiple hardware platforms, such as x86 and Power 8 and 9. In future lessons we will show how to make your environment reproducible (reproducibility being one of the major issues facing science), and Conda allows you to provide your environment to other people across these different platforms.
- Conda allows for using other package management tools (such as
pip) inside Conda environments, where a library or tools is not already packaged for Conda (we’ll show later how to get access to more conda packages via channels).
Additionally, Anaconda provides commonly used data science libraries and tools, such as R, NumPy, SciPy and TensorFlow built using optimised, hardware specific libraries (such as Intel’s MKL or NVIDIA’s CUDA), which provides a speedup without having to change any of your code.
Key Points
Conda is a platform agnostic, open source package and environment management system.
Using a package and environment management tool facilitates portability and reproducibility of (data) science workflows.
Conda solves both the package and environment management problems and targets multiple programming languages. Other open source tools solve either one or the other, or target only a particular programming language.
Anaconda is not only for Python
Working with Environments
Overview
Teaching: 60 min
Exercises: 15 minQuestions
What is a Conda environment?
How do I create (delete) an environment?
How do I activate (deactivate) an environment?
How do I install packages into existing environments using Conda?
How do I find out what packages have been installed in an environment?
How do I find out what environments that exist on my machine?
How do I delete an environment that I no longer need?
Objectives
Understand how Conda environments can improve your research workflow.
Create a new environment.
Activate (deactivate) a particular environment.
Install packages into existing environments using Conda.
List all of the existing environments on your machine.
List all of the installed packages within a particular environment.
Delete an entire environment.
Workspace for Conda environments
If you haven’t done it yet, create a new
conda-environments-for-effective-and-reproducible-researchdirectory on your Desktop in order to maintain a consistent workspace for all the material covered in this course. The Conda environments are not stored there but other files will be.On Mac OSX and Linux running following commands in the Terminal will create the required directory on the Desktop.
$ cd ~/Desktop $ mkdir conda-environments-for-effective-and-reproducible-research $ cd conda-environments-for-effective-and-reproducible-researchFor Windows users you may need to reverse the direction of the slash and run the commands from the command prompt.
> cd ~\Desktop > mkdir conda-environments-for-effective-and-reproducible-research > cd conda-environments-for-effective-and-reproducible-researchAlternatively, you can always “right-click” and “create new folder” on your Desktop. All the commands that are run during the workshop should be run in a terminal within the
conda-environments-for-effective-and-reproducible-researchdirectory.
What is a Conda environment?
A Conda environment is a directory that contains a specific collection of Conda packages that you have installed. For example, you may be working on a research project that requires NumPy 1.24.1 and its dependencies, while another environment associated with an finished project has NumPy 1.12.1 (perhaps because version 1.12 was the most current version of NumPy at the time the project finished). If you change one environment, your other environments are not affected. You can easily activate or deactivate environments, which is how you switch between them.
Avoid installing packages into your
baseConda environmentConda has a default environment called
basethat includes a Python installation and some core system libraries and dependencies of Conda. It is a “best practice” to avoid installing additional packages into yourbasesoftware environment as this can cause dependency complications further down the line. Additional packages needed for a new project should always be installed into a newly created Conda environment.
Conda has a help system
Conda has a built in help system that can be called from the command line if you are unsure of the commands/syntax to use.
$ conda --helpIf you want to read the help on a specific sub-command/action then use
conda <action> --helpfor example to read the help oninstalluse.$ conda install --help
Creating environments
To create a new environment for Python development using conda you can use the conda create command.
$ conda create --name basic-scipy-env
For a list of all commands, take a look at Conda general commands.
It is a good idea to give your environment a meaningful name in order to help yourself remember
the purpose of the environment. While naming things can be difficult, $PROJECT_NAME-env is a
good convention to follow. Sometimes including the version of Python you created the environment
with is useful too.
The command above created a new Conda environment called basic-scipy-env and installed a recent
version of Python (3.10 if you downloaded the most recent install script). You can however specify a specific version of
Python for conda to install when creating the environment by adding a version number e.g. to python=3.8.
$ conda create --name python38-env python=3.8
Activating an existing environment
Activating environments is essential to making the software in environments work well (or sometimes at all!). Activation of an environment does two things.
- Adds entries to
$PATHfor the environment. - Runs any activation scripts that the environment may contain.
Step 2 is particularly important as activation scripts are how packages can set arbitrary environment variables that may
be necessary for their operation. You activate the basic-scipy-env environment by name using the activate command.
$ conda activate basic-scipy-env
You can see that an environment has been activated because the shell prompt will now include the name of the active environment.
(basic-scipy-env) $
Creating and activating a new environment
Create a new environment called “machine-learning-39-env” with Python 3.9 explicitly specified and activate it
Solution
In order to create a new environment you use the
conda createcommand$ conda create --name machine-learning-39-env python=3.9 $ conda activate machine-learning-39-env
Deactivate the current environment
To deactivate the currently active environment use the Conda deactivate command as follows.
(basic-scipy-env) $ conda deactivate
You can see that an environment has been deactivated because the shell prompt will no longer
include the name of the previously active environment, but will return to base.
(base) $
Returning to the
baseenvironmentTo return to the
baseConda environment, it’s better to callconda activatewith no environment specified, rather than to usedeactivate. If you runconda deactivatefrom yourbaseenvironment, you may lose the ability to runcondacommands at all. Don’t worry if you encounter this undesirable state! Just start a new shell orsource ~/.bashrcif you are on a Linux or OSX system.
Activate an existing environment by name
Activate the
machine-learning-39-envenvironment created in the previous challenge by name.Solution
In order to activate an existing environment by name you use the
conda activatecommand as follows.$ conda activate machine-learning-39-env
Deactivate the active environment
Deactivate the
machine-learning-39-envenvironment that you activated in the previous challenge.Solution
In order to deactivate the active environment you could use the
conda deactivatecommand.(active-environment-name) $ conda deactivateOr you could switch back to the
baseconda environment this way.(active-environment-name) $ conda activate
Installing a package into an existing environment
You can install a package into an existing environment using the conda install command. This
command accepts a list of package specifications (i.e., numpy=1.18) and installs a set of
packages consistent with those specifications and compatible with the underlying environment. If
full compatibility cannot be assured, an error is reported and the environment is not changed.
By default the conda install command will install packages into the current, active environment. The following would
activate the basic-scipy-env we created above and install Numba, an open source JIT
(Just In Time) compiler that translates a subset of Python and numpy code into fast machine code, into the active
environment.
$ conda activate basic-scipy-env
$ conda install numba
If version numbers are not explicitly provided, Conda will attempt to install the newest versions of any requested
packages. To accomplish this, Conda may need to update some packages that are already installed or install additional
packages. It is sometimes a good idea to explicitly provide version numbers when installing packages with the conda
install command. For example, the following would install a particular version of Scikit-Learn into the current,
active environment.
$ conda install scikit-learn=1.2
You can specify a version number for each package you wish to install
In order to make your results reproducible and to make it easier for research colleagues to recreate your Conda environments on their machines it is sometimes a good practice to explicitly specify the version number for each package that you install into an environment.
Many packages use semantic versioning where there are three version numbers separated by decimal points e.g. 2.11.3. In this scheme the numbers have this meaning: major_version.minor_version.patch_version. Changes to patch_version are for backwards compatible bug fixes, so we often only specify the first two numbers.
If you are not sure exactly which version of a package you want to use, then you can use search to see what versions are available using the
conda searchcommand.$ conda search <PACKAGE_NAME>For example, if you wanted to see which versions of Scikit-learn, a popular Python library for machine learning, are available, you would run the following.
$ conda search scikit-learnAs always you can run
conda search --helpto learn about available options.
When conda installs a package into an environment it also installs any required dependencies. For example, even though
numpy was not listed as a package to install when numba was installed conda will still install numpy into the environment because it is a required dependency of numba.
You can install multiple packages by listing the packages that you wish to install, optionally including the version you wish to use.
$ conda activate basic-scipy-env
$ conda install ipython matplotlib=3.7 scipy=1.9
What actually happens when I install packages?
During the installation process, files are extracted into the specified environment (defaulting to the current environment if none is specified). Installing the files of a Conda package into an environment can be thought of as changing the directory to an environment, and then downloading and extracting the package and its dependencies. Conda does the hard work of figuring out what dependencies are needed and making sure that they will all work together.
Running the following command in the basic-scipy-env will fail as the requested scipy and numpy versions are
incompatible with Python 3.10 the environment was created with (numpy=1.9.3 is quite an old version).
$ conda install scipy=1.9.3 numpy=1.9.3
Discussion
What are some of the potential benefits of specifying versions of each package, what are some of the potential drawbacks.
Solution
Specifying versions exactly helps make it more likely that the exact results of an analysis will be reproducible e.g. at a later time or on a different computer. However, not all versions of a package will be compatible with all versions of another, so specifying exact versions can make it harder to add or change packages in the future, limiting reusability e.g. with different data.
Freezing installed packages
To prevent existing packages from being updated when using the
conda installcommand, you can use the--freeze-installedoption. This may force Conda to install older versions of the requested packages in order to maintain compatibility with previously installed packages. Using the--freeze-installedoption does not prevent additional dependency packages from being installed.
Installing a package into a specific environment
daskprovides advanced parallelism for data science workflows enabling performance at scale for the core Python data science tools such asnumpy,pandas, andscikit-learn. Have a read through the official documentation for theconda installcommand and see if you can figure out how to installdaskinto themachine-learning-39-envthat you created in the previous challenge.Solution
You can activate the
machine-learning-39-envenvironment, search for available versions ofdaskand then use theconda installcommand as follows.$ conda activate machine-learning-39-env $ conda search dask $ conda install dask=2022.7.0
Listing existing environments
Now that you have created a number of Conda environments on your local machine you have probably forgotten the names of all of the environments and exactly where they live. Fortunately, there is a
condacommand to list all of your existing environments together with their locations.$ conda env list # conda environments: # base * /home/neil/miniconda3 basic-scipy-env /home/neil/miniconda3/envs/basic-scipy-env machine-learning-39-env /home/neil/miniconda3/envs/machine-learning-39-env python310-env /home/neil/miniconda3/envs/python310-env scikit-learn-env /home/neil/miniconda3/envs/scikit-learn-env scikit-learn-kaggle-env /home/neil/miniconda3/envs/scikit-learn-kaggle-envWhere do Conda environments live?
Another method of finding out where your Conda environment live if you’re not sure is to use
conda --infowhich provides the location of the active directory (active env location :) and the location environments are stored (envs directories :) along with additional information.conda info active environment : base active env location : /home/neil/miniconda3 shell level : 1 user config file : /home/neil/.condarc populated config files : /home/neil/miniconda3/.condarc /home/neil/.condarc conda version : 23.1.0 conda-build version : not installed python version : 3.10.8.final.0 virtual packages : __archspec=1=x86_64 __glibc=2.37=0 __linux=6.2.6=0 __unix=0=0 base environment : /home/neil/miniconda3 (writable) conda av data dir : /home/neil/miniconda3/etc/conda conda av metadata url : None channel URLs : https://repo.anaconda.com/pkgs/main/linux-64 https://repo.anaconda.com/pkgs/main/noarch https://repo.anaconda.com/pkgs/r/linux-64 https://repo.anaconda.com/pkgs/r/noarch package cache : /home/neil/miniconda3/pkgs /home/neil/.conda/pkgs envs directories : /home/neil/miniconda3/envs /home/neil/.conda/envs platform : linux-64 user-agent : conda/23.1.0 requests/2.28.1 CPython/3.10.8 Linux/6.2.6-arch1-1 arch/ glibc/2.37 UID:GID : 1000:1000 netrc file : None offline mode : False
Listing the contents of an environment
In addition to forgetting names and locations of Conda environments, at some point you will probably forget exactly what
has been installed in a particular Conda environment. Again, there is a conda command for listing the contents on an
environment. To list the contents of the basic-scipy-env that you created above, run the following command.
$ conda list --name basic-scipy-env
Listing the contents of a particular environment.
List the packages installed in the
machine-learning-envenvironment that you created in a previous challenge.Solution
You can list the packages and their versions installed in
machine-learning-envusing theconda listcommand as follows.$ conda list --name machine-learning-envTo list the packages and their versions installed in the active environment leave off the
--nameoption.$ conda list
Deleting entire environments
Occasionally, you will want to delete an entire environment. Perhaps you were experimenting with conda commands and
you created an environment you have no intention of using; perhaps you no longer need an existing environment and just
want to get rid of cruft on your machine. Whatever the reason, the command to delete an environment is the following.
$ conda remove --name first-conda-env --all
Delete an entire environment
Delete the entire “basic-scipy-env” environment.
Solution
In order to delete an entire environment you use the
conda removecommand as follows.$ conda remove --name basic-scipy-env --all --yesThis command will remove all packages from the named environment before removing the environment itself. The use of the
--yesflag short-circuits the confirmation prompt (and should be used with caution).
Key Points
A Conda environment is a directory that contains a specific collection of Conda packages that you have installed.
You create (remove) a new environment using the
conda create(conda remove) commands.You activate (deactivate) an environment using the
conda activate(conda deactivate) commands.You install packages into environments
conda install.Use the
conda env listcommand to list existing environments and their respective locations.Use the
conda listcommand to list all of the packages installed in an environment.Use the
conda [command] --helpto get information on how to use conda or a specificcommand.
Using Conda Channels and PyPI (pip)
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What are Conda channels?
Why should I be explicit about which channels my research project uses?
What should I do if a Python package isn’t available via a Conda channel?
Objectives
Install a package from a specific channel.
What are Conda channels?
Conda packages are downloaded from
remote channels, which are URLs to directories containing conda packages. The conda command
searches a standard set of channels, referred to as defaults. The defaults channels include:
main: The majority of all new Anaconda, Inc. package builds are hosted here. Included indefaultsas the top priority channel.r: Microsoft R Open conda packages and Anaconda, Inc.’s R conda packages.
Unless otherwise specified, packages installed using conda will be downloaded from the defaults
channels.
The
conda-forgechannelIn addition to the
defaultschannels that are managed by Anaconda Inc., there is another channel that also hasa special status. The Conda-Forge project “is a community led collection of recipes, build infrastructure and distributions for the conda package manager.”
There are a few reasons that you may wish to use the
conda-forgechannel instead of thedefaultschannel maintained by Anaconda:
- Packages on
conda-forgemay be more up-to-date than those on thedefaultschannel.- There are packages on the
conda-forgechannel that aren’t available fromdefaults.
My package isn’t available in the defaults channels! What should I do?
You may find that packages (or often more recent versions of packages!) that you need to
install for your project are not available on the defaults channels. In this case you could try the
following channels.
conda-forge: theconda-forgechannel contains a large number of community curated Conda packages. Typically the most recent versions of packages that are generally available via thedefaultschannel are available onconda-forgefirst.bioconda: thebiocondachannel also contains a large number of Bioinformatics curated conda packages.biocondachannel is meant to be used withconda-forge, you should not worried about using the two channels when installing your prefered packages.
For example, Kaggle publishes a Python 3 API that can be used to interact with Kaggle
datasets, kernels and competition submissions. You can search for the package on the defaults channels but you will
not find it!
$ conda search kaggle
Loading channels: done
No match found for: kaggle. Search: *kaggle*
PackagesNotFoundError: The following packages are not available from current channels:
- kaggle
Current channels:
- https://repo.anaconda.com/pkgs/main/osx-64
- https://repo.anaconda.com/pkgs/main/noarch
- https://repo.anaconda.com/pkgs/free/osx-64
- https://repo.anaconda.com/pkgs/free/noarch
- https://repo.anaconda.com/pkgs/r/osx-64
- https://repo.anaconda.com/pkgs/r/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
Let’s check whether the package exists on at least conda-forge channel.
Note that the official installation instructions
suggest a different way to install.
$ conda search --channel conda-forge kaggle
Loading channels: done
# Name Version Build Channel
kaggle 1.5.3 py27_1 conda-forge
kaggle 1.5.3 py36_1 conda-forge
kaggle 1.5.3 py37_1 conda-forge
kaggle 1.5.4 py27_0 conda-forge
kaggle 1.5.4 py36_0 conda-forge
kaggle 1.5.4 py37_0 conda-forge
.
.
.
kaggle 1.5.12 py38h578d9bd_1 conda-forge
kaggle 1.5.12 py38h578d9bd_2 conda-forge
kaggle 1.5.12 py39hf3d152e_0 conda-forge
kaggle 1.5.12 py39hf3d152e_1 conda-forge
kaggle 1.5.12 py39hf3d152e_2 conda-forge
kaggle 1.5.12 pyhd8ed1ab_4 conda-forge
Or you can also check online at https://anaconda.org/conda-forge/kaggle.
Once we know that the kaggle package is available via conda-forge we can go ahead and install
it.
$ conda create --name machine-learning-env python=3.10
$ conda activate machine-learning-env
$ conda install --channel conda-forge kaggle=1.5.12
Channel priority
You may specify multiple channels for installing packages by passing the
--channelargument multiple times.$ conda install scipy=1.10.0 --channel conda-forge --channel biocondaChannel priority decreases from left to right - the first argument has higher priority than the second. For reference, bioconda is a channel for the conda package manager specializing in bioinformatics software. For those interested in learning more about the Bioconda project, checkout the project’s GitHub page.
Please note that in our example, adding
biocondachannel is irrelevant becausescipyis no longer available onbiocondachannel.
Specifying channels when installing packages
polarsis an alternative topandaswritten in the Rust programming language, so it runs faster.Create a Python 3.10 environment called
fast-analysis-projectwith thepolarspackage. Also include the most recent versions ofjupyterlab(so you have a nice UI) andmatplotlib(so you can make plots) in your environment .Solution
In order to create a new environment we use the
conda createcommand. After making and activating the environment we check what versions ofpolarsare available so we can install explicit version of these. Finally we install the version ofpolarswe wish to use along with the most recent versions ofjupyterlabandmatplotlib(since we do not explicitly state the versions of these).$ mkdir my-computer-vision-project $ cd my-computer-vision-project/ $ conda create --name my-computer-vision-project python=3.10 $ conda activate my-computer-vision-project $ conda search --channel conda-forge polars $ conda install --channel conda-forge jupyterlab polars matplotlibHint: the
--channelargument can also be shortened to-c, for more abbreviations, see also the Conda command reference .
Alternative syntax for installing packages from specific channels
There exists an alternative syntax for installing conda packages from specific channels that more explicitly links the channel being used to install a particular package under the current active environment.
$ conda install conda-forge::polarsRepeat the previous exercise using this alternative syntax to install
python,jupyterlab, andmatplotlibfrom thedefaultchannel andpolarstheconda-forgechannel in an environment calledmy-final-project.Solution
One possibility of doing this is to create the environment
my-final-projectwith an explicit version of Python,activateit, then install the packagesjupyterlabandmatplotlibwithout specifying channel, but prefixingpolarswith theconda-forge::channel.
Using pip and Conda
You can use the default Python package
manager pip to install packages from Python Package Index
(PyPI). However, there are a few potential
issues that you should be aware of when using pip to
install Python packages when using Conda.
First, pip is sometimes installed by default on operating systems where it is used to manage any Python packages
needed by your OS. You do not want to use /usr/bin/pip to install Python packages when using Conda
environments.
(base) $ conda deactivate
$ which python
/usr/bin/python
$ which pip # sometimes installed as pip3
/usr/bin/pip
Windows users…
You can type
where.exein PowerShell and it does the same thing aswhichin bash.
Second, pip is also included in the Miniconda installer where it is used to install and manage OS specific Python
packages required to setup your base Conda environment. You do not want to use this ~/miniconda3/bin/pip to
install Python packages when using Conda environments.
$ conda activate
(base) $ which python
~/miniconda3/bin/python
$ which pip
~/miniconda3/bin/pip
Why should I avoid installing packages into the
baseConda environment?If your
baseConda environment becomes cluttered with a mix ofpipand Conda installed packages it may no longer function. Creating separate Conda environments allows you to delete and recreate environments readily so you dont have to worry about risking your core Conda functionality when mixing packages installed with Conda and Pip.
If you find yourself needing to install a Python package that is only available via PyPI, then you should use the copy of
pip, which is installed automatically when you create a Conda environment with Python, to install the desired package
from PyPI. Using the pip installed in your Conda environment to install Python packages not available via Conda
channels will help you avoid difficult to debug issues that frequently arise when using Python packages installed via a
pip that was not installed inside you Conda environment.
Conda (+Pip)
Pitfalls of using Conda and
piptogether can be avoided by always ensuring your desired environment is active before installing anything usingpip. This can be done by looking at the output ofconda info.
Installing packages into Conda environments using
pipCombo is a comprehensive Python toolbox for combining machine learning models and scores. Model combination can be considered as a subtask of ensemble learning, and has been widely used in real-world tasks and data science competitions like Kaggle.
Activate the
machine-learning-envyou created in a previous challenge and usepipto installcombo.Solution
The following commands will activate the
machine-learning-envand installcombo.$ conda activate machine-learning-env $ pip install combo==0.1.*For more details on using
pipsee the official documentation.
Key Points
A package is a compressed archive file containing system-level libraries, Python or other modules, executable programs and other components, and associated metadata.
A Conda channel is a URL to a directory containing a Conda package(s).
Conda and Pip can be used together effectively.
Sharing Environments
Overview
Teaching: 30 min
Exercises: 15 minQuestions
Why should I share my Conda environment with others?
How do I share my Conda environment with others?
Objectives
Create an environment from a YAML file that can be read by Windows, Mac OS, or Linux.
Create an environment based on exact package versions.
Create a custom kernel for a Conda environment for use inside JupyterLab and Jupyter notebooks.
Sharing Conda environments with other researchers facilitates the reproducibility of your research.
Create an
environment.ymlfile that describes your project’s software environment.
Working with environment files
When working on a collaborative research project it is often the case that your operating system might differ from the operating systems used by your collaborators. Similarly, the operating system used on a remote cluster to which you have access will likely differ from the operating system that you use on your local machine. In these cases it is useful to create an operating system agnostic environment file which you can share with collaborators or use to re-create an environment on a remote cluster.
Creating an environment file
In order to make sure that your environment is truly shareable, you need to make sure that that the contents of your environment are described in such a way that the resulting environment file can be used to re-create your environment on Linux, Mac OS, and Windows. Conda uses YAML (YAML Ain’t Markup Language) for writing its environment files. YAML is a human-readable data-serialization language that is commonly used for configuration files and that uses Python-style indentation to indicate nesting.
Creating your project’s Conda environment from a single environment file is a Conda “best practice”. Not only do you have a file to share with collaborators but you also have a file that can be placed under version control which further enhances the reproducibility of your research project and workflow.
Default
environment.ymlfileNote that by convention Conda environment files are called
environment.yml. As such if you use theconda env createsub-command without passing the--fileoption, thencondawill expect to find a file calledenvironment.ymlin the current working directory and will throw an error if a file with that name can not be found.
Let’s take a look at a few example environment.yml files to give you an idea of how to write your own environment
files.
name: machine-learning-39-env
dependencies:
- ipython
- matplotlib
- pandas
- pip
- python
- scikit-learn
This environment.yml file would create an environment called machine-learning-39-env with the
most current and mutually compatible versions of the listed packages (including all required
dependencies). The newly created environment would be installed inside the ~/miniconda3/envs/
directory, unless we specified a different path using --prefix.
If you prefer you can use explicit versions numbers for all packages:
name: machine-learning-39-env
dependencies:
- ipython=8.8
- matplotlib=3.6
- pandas=1.5
- pip=22.3
- python=3.10
- scikit-learn=1.2
Note that we are only specifying the major and minor version numbers and not the patch or build numbers. Defining the version number by fixing only the major and minor version numbers while allowing the patch version number to vary allows us to use our environment file to update our environment to get any bug fixes whilst still maintaining significant consistency of our Conda environment across updates.
Always version control your
environment.ymlfiles!Version control is a system of keeping track of changes that are made to files, in this case the
environment.ymlfile. It’s really useful to do so if for example you make and update a specific version of a package and you find it breaks something in your environment or when running your code as you then have a record of what it previously was and can revert the changes.There are many systems for version control but the one you are most likely to encounter and we would recommend learning is Git. Unfortunately the topic is too broad to cover in this material but we include the commands to version control your files at the command line using Git.
By version controlling your
environment.ymlfile along with your projects source code you can recreate your environment and results at any particular point in time and you do not need to version control the directory under~/miniconda3/envs/where the environments packages are installed.
Let’s suppose that you want to use the environment.yml file defined above to create a Conda
environment in a sub-directory of some project directory. Here is how you would accomplish this
task.
$ cd ~/Desktop/conda-environments-for-effective-and-reproducible-research
$ mkdir project-dir
$ cd project-dir
Once your project folder is created, create environment.yml using your favourite editor for instance nano.
Finally create a new Conda environment:
$ conda env create --name project-env --file environment.yml
$ conda activate project-env
Note that the above sequence of commands assumes that the environment.yml file is stored within
your project-dir directory.
Automatically generate an environment.yml
To export the packages installed into the previously created machine-learning-39-env you can run the
following command:
$ conda env export --name machine-learning-39-env
When you run this command, you will see the resulting YAML formatted representation of your Conda
environment streamed to the terminal. Recall that we only listed five packages when we
originally created machine-learning-39-env yet from the output of the conda env export command
we see that these five packages result in an environment with roughly 80 dependencies!
What’s in the exported environment.yml file
The exported version of the file looks a bit different to the one we wrote. In addition to version numbers, on some lines we’ve got another code in there e.g.
vs2015_runtime=14.34.31931=h4c5c07a_10. Theh4c5c07a_10is the build variant hash. This appears when the package is different for different operating systems. The implication is that an environment file that contains a build variant hash for one or more of the packages cannot be used on a different operating system to the one it was created on.
To export this list into an environment.yml file, you can use --file option to directly save the
resulting YAML environment into a file. If the target for --file exists it will be over-written so make sure your
filename is unique. So that we do not over-write environment.yaml we save the output to machine-learning-39-env.yaml
instead and add it to the Git repository.
$ conda env export --name machine-learning-39-env --file machine-learning-39-env.yml
$ git init
$ git add machine-learning-39-env.yml
$ git commit -m "Adding machine-learning-39-env.yml config file."
It is important to note that the exported file includes the
prefix:entry which records the location the environment is installed on your system. If you are to share this file with colleagues you should remove this line before doing so as it is highly unlikely their virtual environments will be in the same location. You should also ideally remove the line before committing to Git.
This exported environment file may not consistently produce environments that are reproducible across operating systems. The reason for this is, that it may include operating system specific low-level packages which cannot be used by other operating systems.
If you need an environment file that can produce environments that are reproducible across Mac OS, Windows, and Linux, then you are better off just including only those packages that you have specifically installed.
This is achieved using the --from-history flag/option which means only those packages explicitly installed with
conda install commands, and not the dependencies that were pulled in when doing so will be exported.
$ conda env export --name machine-learning-39-env --from-history --file machine-learning-39-env.yml
$ git add machine-learning-39-env.yml
$ git commit -m "Updates machine-learning-39-env.yml based on environment history"
Excluding build variant hash
In short: to make sure others can reproduce your environment independent of the operating system they use, make sure to add the
--from-historyargument to theconda env exportcommand. This will only include the packages you explicitly installed and the version you requested to be installed. For example if you installednumpy-1.24this will be listed, but if you installedpandaswithout a version and therefore installed the latest thenpandaswill be listed in your environment file without a version number so anyone using your environment file will get the latest version which may not match the version you used. This is one reason to explicitly state the version of a package you wish to install.Without
--from-historythe output may on some occasions include the build variant hash (which can alternatively be removed by editing the environment file). These are often specific to the operating system and including them in your environment file means it will not necessarily work if someone is using a different operating system.Be aware that
--from-historywill omit any packages you have installed usingpip. This may be addressed in future releases. In the meantime, editing your exported environment files by hand is sometimes the best option.
Create a new environment from a YAML file.
Create a new project directory and then create a new
environment.ymlfile inside your project directory with the following contents.name: scikit-learn-env dependencies: - ipython=8.8 - matplotlib=3.6 - pandas=1.5 - pip=22.3 - python=3.10 - scikit-learn=1.2Now use this file to create a new Conda environment. Where is this new environment created? If you are using Git add the YAML file to your repository.
Solution
To create a new environment from a YAML file use the
conda env createsub-command as follows.$ mkdir scikit-learn-project $ cd scikit-learn-project $ conda env create --file scikit-learn-env.yml $ git init $ git add scikit-learn-env.yml $ git commit -m "Adding scikit-learn-env.yml config file"The above sequence of commands will create a new Conda environment inside the
~/miniconda3/envsdirectory (check withconda env listorconda info).You can now run the
conda env listcommand and see that this environment has been created or if you haveconda activate scikit-learn-envyou can useconda infoto get detailed information about the environment.
Specifying channels in the environment.yml
We learnt in the previous episode, that some packages may need to be installed from channels other than the default channel. We can also specify the channels that conda should look for the packages within the
environment.ymlfile:name: polars-env channels: - conda-forge - defaults dependencies: - polars=0.16When the above file is used to create an environment, conda would first look in the
conda-forgechannel for all packages mentioned underdependencies. If they exist in theconda-forgechannel, conda would install them from there, and not look for them indefaultsat all.
Updating an environment
You are unlikely to know ahead of time which packages (and version numbers!) you will need to use for your research project. For example it may be the case that
- one of your core dependencies just released a new version (dependency version number update).
- you need an additional package for data analysis (add a new dependency).
- you have found a better visualization package and no longer need to old visualization package (add new dependency and remove old dependency).
If any of these occurs during the course of your research project, all you need to do is update
the contents of your environment.yml file accordingly and then run the following command.
$ conda env update --name project-env --file environment.yml --prune
$ git add environment.yml
$ git commit -m "Updating environment.yml config file"
The --prune option tells Conda to remove any dependencies that are no longer required from the environment.
Rebuilding a Conda environment from scratch
When working with
environment.ymlfiles it is often just as easy to rebuild the Conda environment from scratch whenever you need to add or remove dependencies. To rebuild a Conda environment from scratch you can pass the--forceoption to theconda env createcommand which will remove any existing environment directory before rebuilding it using the provided environment file.$ conda env create --name project-env --file environment.yml --force
Add Dask to the environment to scale up your analytics
Add
daskto thescikit-learn-env.ymlenvironment file and update the environment. Dask provides advanced parallelism for data science workflows enabling performance at scale for the core Python data science tools such as Numpy Pandas, and Scikit-Learn.Solution
The
scikit-learn-env.ymlfile should now look as follows.name: scikit-learn-env dependencies: - dask=2022.7 - dask-ml=2022.5 - ipython=8.8 - matplotlib=3.6 - pandas=1.5 - pip=22.3 - python=3.10 - scikit-learn=1.2You could use the following command, that will rebuild the environment from scratch with the new Dask dependencies:
$ conda env create --name project-env --file environment.yml --forceOr, if you just want to update the environment in-place with the new Dask dependencies, you can use:
$ conda env update --name project-env --file environment.yml --pruneYou would then add and commit the changes to the
scikit-learn-env.ymlto Git to keep the changes under version control.$ git add scikit-learn-env.yml $ git commit -m "Updating scikit-learn-env.yml with dask"
Installing via pip in environment.yml files
Since you write environment.yml files for all of your projects, you might be wondering how to specify that packages
should be installed using pip in the environment.yml file. Here is an example environment.yml file that uses
pip to install the kaggle and yellowbrick packages.
name: example
dependencies:
- jupyterlab=1.0
- matplotlib=3.1
- pandas=0.24
- scikit-learn=0.21
- pip=22.3
- pip:
- kaggle
- yellowbrick==1.5
Note two things…
pipis installed as a dependency under conda first (under thedependenciessection) with an explicit version (not essential).- Following this there is then an entry for
- pip:and under this is another list (indented further) where double ‘==’ instead of ‘=’ for the explicit version thatpipwill install.In case you are wondering, the Yellowbrick package is a suite of visual diagnostic tools called “Visualizers” that extend the Scikit-Learn API to allow human steering of the model selection process. Recent version of Yellowbrick can also be installed using
condafrom theconda-forgechannel.$ conda install --channel conda-forge yellowbrick=1.2 --name project-env
Key Points