The RSE group organises seminars and promotes seminars from other groups which are of interest to the community. If you have an interesting seminar then announce it on the mailing-list. Below are a number of seminars which are scheduled or have taken place.
We aim to hold lunchtime seminars in the last week of every month, inviting speakers to talk about a wide range of topics that involves practical issues relating to research software.
If you would like to recommend a speaker or would like to give a talk then please contact us. We have a budget to support inviting speakers.
Note: The GPU computing seminar series has now been merged with the RSE seminar series. Talks on GPU computing will be advertised through both mailing lists.
Various, RSE, CMI, N8
Talk: "Best Practices in AI Afternoon 2"

We are excited to present the Best Practices in AI Afternoon 2 which will be held on the 11th of November, 12-5pm at Design Studio 01 (D05), Pam Liversidge Building, Broad Lane, S1 3JD.
The afternoon will consist of talks and walkthroughs on best practices for research, design, development, and deployment of AI. It will focus on practical aspects such as tooling, optimisation, profiling, tips and tricks to supercharge AI in your research!
Buffet lunch and coffee will be provided.
This event is held in collaboration between the Research Software Engineering (RSE) group and the Centre for Machine Intelligence (CMI) in the University of Sheffield, and the N8 CIR.
Register to attend in-person or remotely
Dr Amir Ghalamzan is an Associate Professor at the University of Sheffield and Theme Lead for Robotics and Autonomous Systems at the Centre for Machine Intelligence. He leads the Intelligent Manipulation Lab, where his research focuses on robotic grasping and manipulation, teleoperation, agri-food robotics, robot learning, and haptic and tactile sensors. Amir holds a PhD in Robotics and Automation Engineering from Politecnico di Milano and is committed to advancing data-driven control and planning for real-world robotic challenges, especially in agricultural robotics and tactile perception.
Shaun is a research software engineer at the University of Sheffield with a background in astrochemistry and AI-driven computational chemistry. Since joining the RSE team in December 2024, he’s been exploring how large language models can transform research workflows, from Retrieval Augmented Generation to tool-driven Agentic AI. He’s particularly interested in exploring how to make research software more accessible by the use of natural language as an interface between researchers, their software and their research workflows.
Denis Newman-Griffis (they/them) is a Senior Lecturer in the School of Computer Science and Theme Lead for AI-Enabled Research in the University of Sheffield’s Centre for Machine Intelligence. Their award-winning work investigates the responsible use of AI for human flourishing, including pioneering work on responsible AI in research funding and assessment, ethical practice for AI in policy and public services, and critical perspectives on AI for health and disability. Denis is a British Academy Innovation Fellow and a former Research Fellow of the Research on Research Institute.
Anna Ollerenshaw is a Solutions Architect supporting partners by delivering AI/deep learning solutions. She specialises in conversational AI, particularly speech technology, LLMs, data curation and retrieval augmented generation systems. She has several years experience working in engineering and automation across aerospace, manufacturing and defence, and received her PhD in End-to-End Automatic Speech Recognition (ASR) from the University of Sheffield.
Mozhgan Kabiri Chimeh is a Developer Relations Manager at NVIDIA, focused on growing the AI and accelerated computing ecosystem across the UK and Ireland. In this role, she works with researchers, startups, and industry partners to support the adoption of NVIDIA’s AI software platforms and GPU technologies, helping them accelerate innovation and scale solutions.
Roy Ruddle is a Professor of Computing at the University of Leeds, and Director of Research Technology at the Leeds Institute for Data Analytics (LIDA). Roy has worked in both industry and academia, and specialises in interdisciplinary research into interactive visualization, data quality and data science workflows. His Leeds Virtual Microscope (LVM) has been commercialised by the healthcare company Roche and was a REF2021 Impact Case Study. He was an Alan Turing Institute Fellow from 2018 – 2023, and is currently principal investigator on two major projects: Making Visualization Scalable (MAVIS) for explainable AI (funded by the EPSRC) and AI for Dynamic prescribing optimisation and care integration in multimorbidity (DynAIRx; funded by the NIHR). He has published a practitioner’s guide for rigorously and efficiently checking data quality (https://doi.org/10.5518/1481) and an associated software package as open source (https://pypi.org/project/vizdataquality/).
In-person spaces are limited, please register to attend!
Romain Thomas
Talk: "Better software for better research: Introduction to the FAIR training programme"
As code and software become an ever bigger part of research (it’s likely that around 1/3 of researchers write code), coding and other digital skills become ever more important to researchers. The FAIR for Research Software Principles adapt the FAIR Guiding Principles for Scientific Data Management and Stewardship to Research Software and provide a framework for the development of code and software. The range of skills involved in adopting this paradigm shift is diverse and together the Research Software Engineering (RSE), Data Analytics Service (DAS) and Library teams have developed the FAIR2 for Research Software programme which covers most aspects of the training required.
In this online session, Dr Romain Thomas, Head of Research Software Engineering, will give an overview of the motivation behind the programme’s development and introduce the curriculum covered by the FAIR2 for Research Software programme, explaining the modular structure of the material and how components build on and are linked to each other.
We’ll use sli.do for questions, link will be circulated during the event.
Various, RSE, CMI
Talk: "Best Practices in AI Afternoon"

We are excited to present Best Practices in AI Afternoon which will be held on the 5th of July, 12-6pm at Workroom 2, 38 Mappin, Sheffield, S1 4DT and online.
The afternoon will consist of talks and walkthroughs on best practices for research, design, development, and deployment of AI systems with guest speakers from Nvidia, University of Cambridge and University of Bristol. A focus on practical aspects such as tooling, optimisation, profiling, tips and tricks to supercharge AI in your research!
Buffet lunch and coffee will be provided, with a drinks reception sponsored by Nvidia after the event.
This event is held in collaboration between the Research Software Engineering (RSE) group and the Centre for Machine Intelligence (CMI) in the University of Sheffield.
Karin is a Senior Solutions Architect at NVIDIA, with a specific focus on the Higher Education and Research (HER) industry in the UK. At NVIDIA, she’s leading collaborative efforts with the NVAITC initiative, particularly centred around Isambard-AI. Prior to joining NVIDIA, Karin was a research engineer at Alana AI, where she specialized in Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) systems. Her primary research interests include exploring topic transitions within conversational systems and devising effective strategies for recommendation settings. Karin holds a Ph.D. in Natural Language Processing from Heriot-Watt University, UK, which she completed in July 2023. During her doctoral studies, she focused on advancing conversational AI and recommendation systems. Notably, she contributed to Heriot-Watt’s participation in the Amazon Alexa Prize 2018 competition. Additionally, Karin gained valuable industry experience through an internship at Amazon in 2021, where she worked as an applied scientist on recommendation algorithms.
Ryan is a machine learning engineer at the Accelerate Programme for Scientific Discovery and is interested in driving forward scientific research which is grounded in excellent software engineering and machine learning fundamentals. Before working at Accelerate, Ryan’s research interests explored unconventional approaches to computing using complex physical devices from the world of condensed matter physics.
Wahab finished their PhD in machine learning from the University of Bristol on computer vision applications in biomedicine and material science. They worked as a visiting researcher at the European Space Agency analysing motion capture data of stroke-survivors. More recently working as a machine learning engineer in robotics and aerospace applications. He joined the Isambard AI team in April 2024.
Edwin joined the RSE team in October 2022. He comes from a background in geophysics following a BSc and MSc in Geophysical Sciences at the University of Leeds. After university, he worked in the private sector, developing machine learning (ML) workflows to solve geophysical imaging and inversion problems.
Edwin has practical experience in the designing, training and evaluation of ML models. He is experienced in Python having worked with data science libraries such as Numpy, Pandas, Scikit-learn, Tensorflow and Keras. He has a growing interest in MLOps (Machine Learning Operations) and the practical challenges of scaling up ML practices.
Bob works in the Modernising Medical Microbiology group in the Nuffield Department of Medicine on software as a service platforms for infectious disease diagnostics, public health and research applications.
He has collaborated with a wide range of academic, public and private sector partners including GPAS, AirQo, Institut Pasteur, the UK Health Security Agency and Health Data Research UK. Bob has been a maintainer and a reviewer for The Carpentries, and has contributed to more than 20 peer-reviewed publications, including one in Nature. He is currently interested in technologies and working practises that result in useful research software.
Book a 15 to 30 minutes 1 to 1 meeting with Nvidia experts on the day! They are open to discuss your research project at any stage whether you are already familiar and use accelerated computing looking to optimise or scale your project or whether you are relatively new and want to explore how to use AI/HPC in your project. Example discussion topics include:
Nvidia experts on the day:
In-person meetings will take place on the day and slots are limited and are first come, first served. Remote meetings (may not happen on the day) will be offered once we’ve run out of meeting slots.
Various, Research IT
Talk: "Research-IT Forum: Analysing Human Language: Mining Textual Data and Natural Language Processing"
This event is being run by Research IT
The Research-IT forum is a regular event providing updates on developments relating to research computing covering research software, computational science, data science, qualitative and quantitative analysis and the management of research outputs. It is a forum where researchers can showcase their work in an environment conducive to creative discussion.
This event will explore data mining and natural language processing at the University. Our six speakers, from various departments, will present their specific research and the topics range from analysing social media speech to corpus analysis.
To register, please go to: https://www.eventbrite.co.uk/e/210987929577/
For more information about the event, please visit: https://newsrcg.blogspot.com/2021/11/research-it-forum-analysing-human.html
Jens Krinke, University College London
Talk: "Toxic Code on Stack Overflow"
This event is being run by the Testing Research Group
Software developers use Stack Overflow to interact and exchange code snippets and research uses Stack Overflow to harvest code snippets for use with recommendation systems. However, code on Stack Overflow may have quality issues, such as security or license problems. In this talk I will present our work on how users of Stack Overflow perceive such issues, how we studied the problem of outdated code and potential license violations, and how code is non-compliant with coding style. The prevalence of such toxic code may affect mining or machine learning tasks using Stack Overflow as a code base.
Google meet link: https://meet.google.com/zbx-hhot-ucp
Will Furnass, Joe Heffer, Gemma Ives
Talk: "The software and people behind academic research"
This event was part of the Sheffield Digital festival.
The use of data and computational analysis in research is increasing and it is critical in getting new insights. But how does the code that drives this research get written? What is different about writing software in a research environment? What are the challenges around data management and infrastructure? And how can visualisation technologies make the outputs of research of greater value and interest to other researchers and the public?
Much of modern research is facilitated by code that researchers have had a hand in writing. In this first talk we explore the processes through which research ideas are encapsulated as software, which often involves interactive data exploration, then how this software evolves (or not) over time. We also discuss the computational demands of research and common technologies, before concluding with a look at challenges relating to the development of coding skills in academia, the drive for reproducible research, and how funding and incentives shape the research software lifecycle.
We provided software engineering expertise for researchers from The University of Sheffield who are participating in the COVID-19 Genomics UK (COG-UK) Consortium which provides large-scale, rapid genomic sequencing to guide the public health response to the pandemic.
More and more often researchers are openly sharing their research data and their findings, encouraging engagement and scrutiny from politicians and the public. This final talk will discuss how and why data visualisation is becoming an essential skill in academic research.
Paul Richmond, others to be confirmed, N8
Talk: "Bede Introductory Event"
This introductory event hosted by the N8 CIR offers those who are new to HPC the opportunity to learn more about Bede’s hardware and software, as well as the support that is available to users, regardless of their experience of HPC.
Bede is the N8’s newest high performance computing (HPC) platform. Since its formal launch in December 2020 researchers have been using the system across a range of academic domains to accelerate their research.
This event will feature information regarding the Bede platform, support available for it and case studies highlighting how it is already being used beneficially in research. One of the case studies will be presented by our very own Dr Paul Richmond, discussing the upcoming FLAME GPU 2 software and its use on Bede.
Anna Krystalli, White Rose PGR, Open Research Workshop
Talk: "Putting the R into Reproducible Research"
R and its ecosystem of packages offers a wide variety of statistical and graphical techniques and is increasing in popularity as the tool of choice for data analysis in academia.
In addition to its powerful analytical features, the R ecosystem provides a large number of tools and conventions to help support more open, robust and reproducible research. This includes tools for managing research projects, building robust analysis workflows, documenting data and code, testing code and disseminating and sharing analyses.
In this talk we’ll take a whistle-stop tour of the breadth of available tools, demonstrating the ways R and the Rstudio integrated development environment can be used to underpin more open reproducible research and facilitate best practice
Anna Krystalli, The University of Sheffield, Open Research Conversation: Reproducibility in Practice
Talk: "ReproHacks: Practicing reproducibility makes better"
Join us for a discussion on the importance of reproducibility and the challenges faced when attempting to reproduce others’ research.
Reproducibility, recreating the results others have found in their research, presents many challenges for researchers, with several studies suggesting that much published cannot be reproduced. The University of Sheffield has an active reproducibility network, is a member of the UK Reproducibility Network and has created a new post of Research Practice Lead. This event will include presentations and discussions on reproducibility and the practical lessons learnt from running ReproHacks. Speakers will include:
This event is part of a series of Open Research Conversations facilitated by The University of Sheffield Library, which include talks from researchers and other experts to share their experiences, promote best practices and discuss the challenges they are facing. Have a look at our other events and sign up here.
In this talk, I introduce ReproHacks, one day reproducbility hackathons, where participants attempt to reproduce research from associated published code and data. I discuss the importance of providing space to practice reproducibility, some of the lessons learnt from running ReproHack events so far and some thoughts on moving forward.
Materials (slides) associated with the event can be found at doi.org/10.15131/shef.data.13516274.v1
Twin Karmakharm
Talk: "Singularity for HPC"
Twin Karmakharm gave a talk on Singularity for HPC at the HPC Champions event. The talk gives an introduction to the Singularity container technology and experiences learned from its uses at the University of Sheffield.
Twin Karmakharm
Talk: "Update on JADE and JADE 2 Tier 2 GPU-eqipped HPC systems"
Twin Karmakharm gave short update on the state of JADE and JADE 2 Tier 2 GPU-equipped HPC systems at the HPC Champions event.
Will Furnass
Talk: "Deep Learning at TUOS: workflows, tooling and platforms"
The Faculty of Engineering at TUOS and the AMRC are to hold a two-hour workshop on data science to help better identify relevant opportunities and collaborators for future AMRC projects.
At this workshop the RSE team will provide a brief overview of:
Bob Turner and Will Furnass
Talk: "Reproducible research through software"
Bob Turner and Will Furnass from the RSE team talked about methods and tools for reproducible computational workflows at one of ScHARR’s Statistics Academic Group’s regular seminars, covering:
TBC, N8
Talk: "N8 CIR Meet-Ups – N8 CIR RSE Highlights"
A set of four short talks from research software engineers working within the N8 Research Partnership. Full details of the speakers are yet to be confirmed. Full details will be published here closer to the event: https://n8cir.org.uk/events/n8-cir-meet-ups-5/
Mark Turner, N8
Talk: "N8 CIR Meet-Ups – RSE Career Progression"
In this session Mark Turner (University of Newcastle) will explain some of the work done with Human Resources departments to set roles and responsibilities for each job grade from new RSEs to group leaders. There will also be feedback from senior RSEs who have sat on interview panels.
Find out more here: https://n8cir.org.uk/events/n8-cir-meet-ups-4/
TBC, N8
Talk: "N8 CIR Meet-Ups – N8 CIR RSE Highlights"
A set of four short talks from research software engineers working within the N8 Research Partnership. Full details of the speakers are yet to be confirmed.
Full details will be published here closer to the event: https://n8cir.org.uk/events/n8-cir-meet-ups-3/
Alan Real and Paul Richmond, N8
Talk: "Introducing the N8 Bede GPU HPC cluster"
Following a successful EPSRC application, the N8 Centre for Computationally Intensive Research (N8 CIR) will soon host a new national Tier-2 HPC service, called Bede.
Bede is a novel architecture supercomputer based upon IBM Power 9 CPUs and NVIDIA Volta GPUs. This architecture supports memory coherence between the GPU and CPU and a hierarchy of interconnects to allow effective distributed GPU use. This architecture will extend the size of problems that can tackled beyond that of other GPU-accelerated architectures, increasing data sizes for accelerated simulation and analysis codes, and reducing the ‘time to science’ for a range of ‘hard’ problems.
The purpose of this facility is to enable new science across many different disciplines. The machine will be hosted by Durham University.
In this session Alan Real (Durham University) will introduce the machine and Paul Richmond (RSE team, University of Sheffield) will introduce some of the GPU work he has been doing and highlight the potential of GPUs for computational research.
This event is only open to those working or studying at one of the N8 Universities.
Anna Krystalli, University of Sheffield
Talk: "Putting the R into Reproducible Research: Director's Cut"
Introductions
Is your statistical software correct?
Performing modern statistical research is almost impossible without the aid of software. Many of us use statistical software to one degree or another – from small analyses in Microsoft Excel through to R or Python Scripts on our laptops right up to large machine learning pipelines in the cloud.
How can we be sure that our computational results are correct when we employ these techniques? In this talk, I will discuss what can go wrong and strategies we can employ to increase the probability that our computational research gives the right answer.
Putting the R into Reproducible Research
R and its ecosystem of packages offers a wide variety of statistical and graphical techniques and is increasing in popularity as the tool of choice for data analysis in academia.In addition to its powerful analytical features, the R ecosystem provides a large number of tools and conventions to help support more open, robust and reproducible research. This includes tools for managing research projects, building robust analysis workflows, documenting data and code, testing code and disseminating and sharing analyses.In this talk we’ll take a whistle-stop tour of the breadth of available tools, demonstrating the ways R and the Rstudio integrated development environment can be used to underpin more open reproducible research and facilitate best practice
The committee and our speakers will stay online for a few more minutes to wrap up any discussions
Alberto Biancardi , University of Sheffield
Talk: "[POSTPONED] Object Oriented Programming in MATLAB?"
UPDATE: this has been postponed and will be rescheduled shortly.
Abstract: In the context of MATLAB, Object-oriented programming (OOP) offers a convenient way of creating new capabilities that are easily customised to specific needs. This talk will describe the basics of how OOP is handled in MATLAB, some selected cases where OOP is used within MATLAB itself, and then some examples, mostly from my personal experience in image computing, to illustrate how turning to OOP can help achieve two core outcomes:
Bio: Alberto Biancardi is an Image Computing Scientist in the POLARIS group, Department of Infection, Immunity & Cardiovascular Disease, The University of Sheffield. His focus is on the analysis of images of the lungs, both structural and functional, reflecting the group’s expertise in the use of hyperpolarised noble gases in magnetic resonance imaging.
Martin Callaghan, University of Leeds
Talk: "From laptop to HPC to cloud: How to containerise your workflow to make it portable and reproducible"
Abstract:
In this talk I’ll discuss a number of use-cases for containerising your research codes and applications using both the Docker and Singularity ecosystems.
I’ll demonstrate the NVIDIA HPC Container Maker language (write your container definitions once to create both Docker and Singularity definitions) and how to combine Git, Github, Dockerhub and Singularity Hub to create a continuous test and development pipeline for your containers which you can then go on to use on your Desktop, in the Cloud or on HPC.
Bio:
I’m Research Computing Manager and lead the Research Computing team at the University of Leeds.
Our team provides Research Infrastructures (including Cloud and High Performance Computing), Programming and Software Development consultancy across the University’s diverse research community.
My role is part Research Software Engineer, part trainer, part consultant and part manager, including running Research Computing’s comprehensive training programme for research staff and students.
My personal research interests are in text analytics, particularly using neural networks to summarise text at scale.
David Jones, University of Sheffield
Talk: "CANCELLED - What is Garbage, and Why are we still Collecting it after 50 years?"
Please note: this event has been CANCELLED.
Abstract: Garbage Collection is a way of automatically reclaiming and reusing program memory that is no longer needed. It was invented in 1959 by John McCarthy as part of the implementation of the programming language LISP. A language with garbage collection means the programmer never has to worry about free’ing memory and frees their intellect to work on more interesting problems.
Once the province of languages that were regarded as esoteric and slow, garbage collection is now in every dominant language in use today (Java, R, Python, Ruby, Go, Lua, Lisp).
I give an overview of garbage collection algorithms and discuss some of the trade-offs that affect space/time performance, ease of implementation, and portability. We’ll have a brief splash around inside the implementation of the programming language Lua (PUC-Rio, Brazil).
Bio: David is a Research Software Engineer in the University of Sheffield’s RSE group.
David graduated from the University of Cambridge with a degree in mathematics and a Post-Graduate Diploma in Computer Science, and has since taken a variety of mostly systems programming roles in industry before recently being employed in The Academy.
David has expertise in C, Python, Go, Lua, embedded microcontrollers, programming language runtimes, Software Engineering Management, /bin/awk, and the PNG image format.
Chris Bording, IBM
Talk: "Virtualisation for Scientific Computing"
Abstract: Basic prime on using Virtual Compute Resources to do Science!
Based on my experiences working at a number of universities and in industry supporting researchers and helping them to migrate their computational work to HPC resources, there is a significant gap in the knowledge of a majority of researcher in how to do this migration from their laptop/desktop to HPC. What I have identified is that having access to virtual compute resource can help close this knowledge gap and improve the basic compute skills of researchers and greatly reduce the effort when taking that final step of migrating work to HPC resources.
There are a number of open source tools available that enable people to use virtual machines and we will talk about Virtualbox and Vagrant. Will cover how to setup the environments and integrate the virtual systems into your work. The basics of DEVOPS so you can work in a more collaborative and sustainable environment.
Bio: Chris Bording, is a Research Staff Member- Senior IT Architect Research User Support Environment with IBM Research in Daresbury. Chris’ areas of interest are in supporting scientific computing with High Performance Computing resources and developing virtual resources to support an array of scientific research projects. Leads several open source tools that are focused on make HPC and Cloud resources easier to support and use. He is also certified Software Carpentry trainer and regularly gives training at the Hartree Centre.
Rich FitzJohn, Imperial College London
Talk: "Fast and high-level solutions of ordinary differential equations with odin"
Abstract: Researchers often have to make trade-offs between expressiveness and performance when implementing their models. For sufficiently specific problems, these trade-offs can be removed by interfaces that reduce the gap between the way they would describe their problem and optimal ways for a computer to solve it.Ordinary Differential Equations (ODEs) turn up in many areas of infectious disease modelling and represent a trade-off of this form, especially in high-level languages such as R. We have developed a new R package “odin” (https://mrc-ide.github.io/odin) to reduce this trade-off by creating a domain specific language (DSL) hosted in R that compiles a subset of R to C in order to efficiently express and solve ODEs.
I will present applications of “odin” both in a research context for implementing epidemiological models with 10’s of thousands of equations and in teaching contexts where we are using the introspection built into the DSL to automatically generate interactive web-based interfaces. I will also discuss how our RSE group works to support a large group of epidemiological modellers, how we use agile processes to manage our development, and to briefly highlight other tools from our group that help with general problems.
Bio: Rich has been a research software engineer in the “RESIDE” group (https://reside-ic.github.io/) at the Department of Infectious Disease Epidemiology and MRC Centre for Global Infectious Disease Analysis for the last 4 years. His focuses are infrastructure and tools that generalise problems common to research groups across the department. He is interested in reproducible research and in helping researchers get more science done per line of code that they write. Before moving to work full-time as an RSE, his research career involved modelling coexistence in tropical forests, diversification over macro-evolutionary timescales and the potential for gene flow from genetically-modified crops.
Ian Sudbery, University of Sheffield
Talk: "Going with the flow: Using workflow managers to co-ordinate multistep analysis pipelines across multiple compute nodes in a reproducible manner. "
Abstract: High performance compute facilities were originally envisaged to run single, monolithic programs that could run across multiple compute nodes. However many scientific analyses consist of a “pipeline” of smaller, interdependent tasks, with each step consisting of transforming, combining or summarizing data in some fashion or another. While each job will generally use only a small amount of resources (e.g. a single core, or a small number of cores on a single machine), a complete analysis will consist of running many of these smaller jobs for different input files(or subsets of input files) in an “embarrassingly parallel” manner. Orchestrating such an analysis and tracking the dependencies across multiple analysis steps manually can be a confusing, time consuming and error prone-task. Software tools that track dependencies in a pipeline are not new, with the oldest and most well known example being make, but a new generation of tools, designed specially with data analysis pipelines in mind has appeared in the last few years. Such systems allow the coordination of the many steps of an analysis into a reproducible/reusable recipe or script, handle submission of jobs that can be run in parallel to compute clusters (or even cloud appliances) and restarting half-finished analyses and log metadata about pipeline runs. They can be used to generate production grade, reusable systems, or as computational lab book that eases record keeping and distribution of prototype analyses across clusters.
I will review the common systems, the advantages of using them, and give a demonstration of developing a simple pipeline using one example tool: the CGAT-core/ruffus system.
Bio: Ian Sudbery is a Lecturer in Bioinformatics. He began his career as a wet-lab scientist working in Genomics and System Biology (in Cambridge and Boston, MA respectively), before laying down his pipettes and taking up the keyboard and code. A graduate of the MRC CGAT program to retrain lab scientists in computation, he joined the University of Sheffield in 2014 where he heads a group of 6 PhD students and postdocs studying Gene Regulation and its break down in disease, mainly through the analysis of high-throughput DNA and RNA sequencing data.
Phil Tooley, Numerical Algorithms Group (NAG)
Talk: "HPC the easier way: Tools and techniques for managing software and making the most of your High Performance Computing resources"
Abstract: Modern HPC infrastructure such as ShARC at the University of Sheffield allows researchers across a broad range of fields access to resources for solving computationally complex problems. However, accessing and making best use of these resources is not always straightforward. Common problems faced by researchers wishing to use HPCs include difficulty in building the software packages that they need to use, as well as locating the documentation and information to enable them to make most efficient use of the available resources.
In this seminar I will describe some common problems faced by HPC users and demonstrate some of the available tools and techniques to overcome them. In particular I will look at how to use information gathered from previous jobs to choose the optimum parameters to submit a job with, optimising for minimum queuing time and maximum efficiency. I will also tackle the problem of installing software and dependencies, highlighting how package managers such as Conda and S-pack can be used to manage the installation of software. Using package managers can vastly reduce the complexity and time needed to manage research software as well as increasing reliability for the user.
Bio: Phil Tooley was a member of the RSE team here in Sheffield before leaving to take on the role of HPC Application analyst at the Numerical Algorithms group. He is a former theoretical and computational plasma physicist with particular interest in mathematical modelling, code optimisation and parallelism. He is an experienced developer of “traditional” parallel HPC codes using MPI and OpenMP in C, C++ and Fortran, but also champions the use of the Numpy/Scipy stack for scientific computing with python. This includes the use of accelerator technologies including Numba and Cython to write custom python code which is speed competitive with traditional compiled languages, possible in conjunction with parallel frameworks such as Dask.
Will Furnass, University of Sheffield
Talk: "'But it worked on my computer!' - curating research computing environments (lightning talk at University of Sheffield Reproducibility Showcase)"
On 27th June 2019 the university will host its first Reproducibility Showcase. The aim is to showcase current good practices at Sheffield and identify the challenges that make reproducing our research difficult.
This event will interest everyone who has wondered about the reliability of research they read in journals, thought about the best way to do their own research, or who is interested in innovations which are helping make research more reliable and open.
It includes a keynote from Professor Marcus Munafò, University of Bristol and UK Reproducibility Network lead: “Scientific Ecosystems and Research Reproducibility”. Also, Will Furnass from the RSE team will be giving a short talk on the challenges of curating research computing environments to make workflows (more) reproducible. The agenda:
Hannah Sewell, Sky Betting and Gaming
Talk: "CANCELLED: Transitioning into the tech Industry from a PhD"
Unfortunately we’ve had to cancel this event as the speaker is no longer available.
Abstract: Writing code in your PhD and in industry are wildly different. From the processes surrounding getting your code out into live to the way you work in a team, industry has its own set of rules to learn in order to become an effective software engineer. Having gone from working on code that maybe my PhD supervisor would flick through to helping to build a login used by 1500 customers a second the past 8 months have been enormous learning curve. In this talk I will discuss some of the differences I have experienced between writing code in your PhD and writing code in a large company. I’ll discuss the best practices we carry out as Login and Recovery Squad at Sky Bet, what its like to work in industry and what I wish I’d done with my code during my PhD in plant genetics.
Bio: Dr Hannah Sewell is a software engineer at Sky Betting and Gaming in the Login and Recovery Squad. She carried out her PhD in Quantitative Genetics in Animal and Plant Science at The University of Sheffield, finishing in 2018. She first learned to code through Code First: Girls HTML and CSS course and now codes predominantly in Javascript doing full stack web development.
Luke Mason, Application Performance Engineering Group Leader at Hartree Center
Talk: "Software Outlook"
Abstract: Software Outlook is a project funded by the EPSRC as part of the Computational Science Centre for Research Communities. It aims to support the UK’s Collaborative Computational Projects (CCPs) and High-End Computing (HEC) Consortia in the development and optimisation of their world-leading software. These activities include
The challenges faced by CCP’s and HEC consortia in modernising their codes are fed directly into Software Outlook’s remit. During this talk, we will discuss these challenges and the subsequent work being done by Software Outlook.
Bio: Luke leads the High Performance Software Engineering group at the Hartree Centre. The group specialises in code scalability and performance on HPC (high performance computing) systems as well as porting and optimisation for emerging and novel architectures. He is experienced in working alongside both industrial and academic scientists to produce accurate and efficient code across a range of disciplines and architectures. His group is involved in development for the Met Office and the EPSRC funded “Big Hypotheses” project, to name just a few of its current activities.
Tania Allard, Microsoft
Talk: "Machine learning at scale and in research: how different are they and what can they learn from each other?"
Abstract: The last decade has seen the largest growth in the areas of theoretical and applied machine learning, deep learning, and artificial intelligence of all history. This is in part due to the widespread availability of better, more powerful and cheaper computational resources than ever before. Another factor leading to this growth is the embedding of research machine learning groups in larger corporations. As a consequence, we have seen the emergence of ‘data powered’ services and applications in almost any industry, from retail and fintech to highly regulated areas such as healthcare and security.
Although the practice of embedding research scientists in startups and companies providing machine learning services has become more common there is still the belief that production and research and development ML are fundamentally different. When the truth is, they are both different sides of the same coin. But there is yet another question to ask: how different is industrial to academic research (in machine learning and data science) and what practices can and should be cross-pollinated from one environment to the other?
In this talk, I will cover the infrastructure and software practices which make it possible to serve ML services to the wider population at scale. I will then compare the industrial and academic machine learning research practices and provide insight into industry practices that could be adapted by researchers to improve their outputs, workflows, foster reproducible and transparent science and work collaboratively to solve global challenges.
By the end of the talk, the attendees will be better informed about the technologies that could improve and boost machine learning and data science research and practices.
Bio: Tania is a Developer Advocate with vast experience in academic research and industrial environments. Her main areas of expertise are within data-intensive applications, scientific computing, and machine learning. One of her main areas of expertise is the improvement of processes, reproducibility, and transparency in research, data science and artificial intelligence. Over the last few years, she has trained hundreds of people on scientific computing reproducible workflows and ML models testing, monitoring and scaling and delivered talks on the topic worldwide.

Phil Tooley, University of Sheffield
Talk: "Here there be dragons: The HPC code development journey"
Abstract: Developing high performance codes, especially parallel codes can be a complex and time consuming process. In this talk I will describe the general process of taking a serial code or algorithm and developing a high performance parallel version using modern techniques and libraries, using my own projects as examples. I will discuss some of the available high level frameworks available in several languages and their advantages and drawbacks, and compare this to more traditional low level development using MPI or CUDA. Following this I will describe methods for testing, benchmarking and profiling of HPC codes using open source tools and free services. Finally I will discuss strategies for ensuring that software is sustainably developed to ensure that it is straightforwardly portable to other hardware and easily accessible to other users.
Dr Christopher Woods, University of Bristol
Talk: "Running Serverless HPC Workloads on Top of Kubernetes and Jupyter Notebooks"
Abstract: The cloud holds the promise of a new way to perform digital science - interactive, elastically scaling, open data, open compute, and sharing reproducible workflows to collaboratively solve global grand challenge problems. The Research Software Engineering group at Bristol work with most of the major public cloud companies (Amazon, Google, IBM, Microsoft and Oracle) on a range of projects creating everything from elastically scaling slurm clusters, through workflows for Cryo-EM image refinement, to national platforms for tracking UK greenhouse gas emissions. Through this, we’ve recognised that comparing the cloud to on-premise HPC is like comparing a fixed-line telephone to a smartphone. Just as an iPhone is more than just a mobile telephone, so the cloud is more than just an “on-demand cluster”.
To this end, via all of our projects, we have been gradually building Acquire. Acquire provides multi-cloud identity and access management to cloud-based storage and compute services. Acquire is designed to make it easy for HPC jobs to be run interactively within Jupyter notebooks. Jupyter notebooks, deployed on top of kubernetes (k8s), are finding rapid adoption in universities and industry. While k8s can spawn new pods for each notebook session, launching high performance computing (HPC) jobs during dynamic workflows, and then managing access to the resulting output data is complicated. Acquire builds on top of the Fn serverless framework (https://fnproject.io) to deploy individual simulations as Fn functions that are called dynamically from workflows run within Jupyter notebooks. A notebook running on a lightweight k8s cluster can burst HPC workloads via Fn serverless calls to a dynamically provisioned cluster running on a bare metal or VM-based HPC/GPU cloud. Using Fn, we are constructing a distributed identity, access, and accounting layer around dynamically scaling compute resources and globally distributed object stores. This adds security and accountability, thereby making it easy for end users to manage complex multi-cloud workflows. Researchers can control costs by translating billing into units of “simulation” rather than “core hours”, and will be able to publish and share the results via access-controlled DOIs. Altogether, Acquire will help us realise the potential of the cloud as a truly planetary supercomputer. Put more succinctly, Acquire is helping us build the Netflix of simulation.
Bio: Christopher is an EPSRC Research Software Engineering (RSE) Fellow, managing the RSE Group in the Advanced Computing Research Centre at the University of Bristol. Christopher’s started his research career as a computational chemist, developing new methods and software for biomolecular simulation (https://protoms.org, https://siremol.org). This software is now sold and used in the pharmaceutical industry (https://www.cresset-group.com/flare/). Christopher’s aim is to improve the quality and sustainability of research software by raising awareness of the importance of software engineering skills, and advocating the development of sustainable funding pathways and careers for people who develop research software. Christopher is joint-chair of the Research Software Engineering Association (https://rse.ac.uk). He provides software engineering training to researchers across the UK (https://chryswoods.com/main/courses), and regularly provides advice to universities on how to set up and manage successful RSE teams.
From a start in computational chemistry, Christopher’s research now covers software engineering in everything from monitoring greenhouse gases, via manufacturing airplane components, to resolving Cryo-EM images and managing complex biomolecular simulation and data analysis workflows. Most of these projects now require developing and adapting software for the cloud. As such, the Bristol RSE group has a growing international reputation for being at the forefront of cloud software engineering research. Christopher contributes to long-term UK cloud strategy via close working relationships with engineers at many of the public cloud companies, and membership of the EPSRC eInfrastructure Strategic Advisory Team and UKRI eInfrastructure expert group.
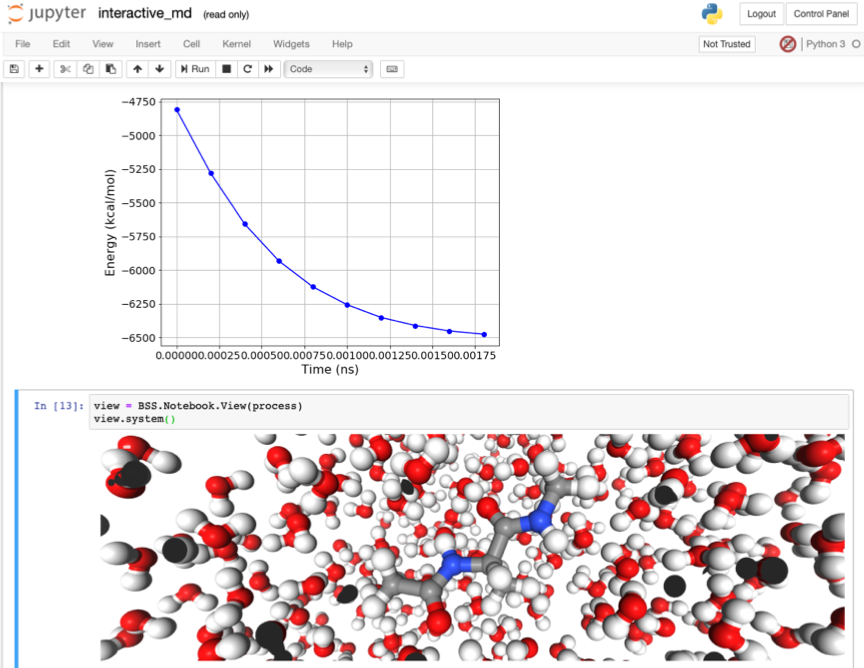
Will Furnass, David Jones, University of Sheffield
Talk: "A short talk on AWK and a slightly longer talk on conda"
Heralded by some[1] as “235 times faster than hadoop”,
AWK is a programmable text processing tool that
has been packaged with Unix, since 1979-ish,
and has been in all major Unix standards since.
AWK builds on the grep and sed tools,
borrowing some of their syntax and style in
a tool that is almost as concise but fully programmable.
AWK is good at cutting through text-based datasets at blazing speed.
David will introduce you to some of its ways.
Slides and notes: https://gitlab.com/drj11/talk-awk
[1] https://adamdrake.com/command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html
conda is a tool for creating isolated environments of software
packages. Over the last few years it has greatly simplified the
challenge of providing the software dependencies required for many
research computing workflows and it allows certain workflows to be
easily reproduced on different hardware and operating systems (e.g. in
the cloud or on HPC systems). In this talk Will covers: what problems
conda tries to solve, the basics of using conda, alternative tools
that address similar problems and issues that may arise when using
conda.
Slides and source for slides.
Dr Christopher Woods, University of Bristol
Talk: "How to design and engineer good code for research."
Abstract: The code you write to analyse your data and conduct your work is a valuable research tool. Understanding how to write good research code and software is very important. A broad range of skills are needed to ensure that software is sustainable, and that it fulfils research software’s unique requirements of being trustably correct, flexible, and performance portable. Research Software Engineering is a discipline that embraces these skills. Research software engineers (RSEs) employ tools such as documentation, version control and unit testing to ensure software is trustably correct. They use modular, component-based design to ensure that software is flexible and performance portable. Finally, an emerging career path for research software engineers in both academia and industry is supporting teams who now enhance the sustainability, quality and capability of research software, and provide training in research software engineering best practice to the next generation of researchers.
Dr Spiridon Siouris, University of Sheffield
Talk: "Taking up development of existing research codes. A discussion on common issues and effective ways of dealing with them"
Abstract: Research codes in Engineering are written with the aim of generating results as quick as possible so that interesting physical phenomena can be analysed. However, time constraints, lack of formal training in Computer Science/Software development, and pressure for results leads to software that can be problematic. In this talk we will discuss about:
Bio: Dr. Spiridon Siouris is a Research Fellow in the Low Carbon Combustion Group in Mechanical Engineering at The University of Sheffield. His research is focused on modeling chemically reacting flows in gas turbine fuel and lubrication systems using CFD and lower order modelling codes. Currently he is working on further developing a CFD code in which wall boundaries can deform according to deposition growth layers due to thermal oxidative degradation in jet fuels (FINCAP project with Rolls Royce). For over a decade he has been involved in numerous software projects for aerospace applications, and has worked alongside students, PhD researchers, and professional engineers developing modeling software. He has been exposed to a wide range in quality of coding, and his enthusiasm for computers, programming and engineering, drive him to educate people towards developing high quality software.

Phil Tooley and Will Furnass (RSE team), University of Sheffield
Talk: "Make it right, then make it go fast enough"
Abstract: The theory seminar group in the Department of Physics invited RSE Sheffield to give a talk on code optimisation. We took this opportunity to stress the importance of ensuring, using tests, that code is correct before and after optimisation and the value of profiling methods and tools to ensure that optimisation efforts are precisely targetted. We finished the talk by focussing on the things that most greatly contribute to software being sustainble: version control, test frameworks and automated testing and good documentation.
Bio: Phil and Will are Research Software Engineers in the University of Sheffield’s RSE group.

Andrew Turner, EPCC
Talk: "Open source UK HPC benchmarking"
Abstract: The recent investments in national HPC services in the UK (for example the national Tier2 HPC services and DiRAC 2.5x) and the offerings from public cloud providers have led to a wider range of advanced computing architectures available to UK-based researchers. We have undertaken a comparative benchmarking exercise across these different services to help improve our understanding of the performance characteristics of these platforms and help researchers choose the best services for different stages of their research workflows. In this seminar we will present results comparing the performance of different architectures for traditional HPC applications (e.g. CFD, periodic electronic structure) and synthetic benchmarks (for assessing I/O and interconnect performance limits). We will also describe how we have used an open research model where all the results and analysis methodologies are publicly available at all times. We will comment on the ease (or not) of compiling applications on the different platforms in a performant way, assess the strengths and weakness of architectures for different workloads, and demonstrate the benefits of working in an open way
Benchmarking repository: https://github.com/hpc-uk/archer-benchmarks
Bio: Andy works for EPCC at the University of Edinburgh and has a particular focus on helping users get the best from the national HPC services around the UK. Much of his recent work has focussed on achieving this through an open benchmarking exercise comparing performance across different HPC systems and different applications and by developing HPC Carpentry training to provide researchers with the tools they need to use advanced computing in their research.

Rob Baxter, EPCC
Talk: "Don’t Panic! Demystifying Big Data, Data Science and all that."
Abstract: The world’s digital data are still doubling in number every year or so, and research is a big culprit. Whether you measure it by volume, velocity or variety, research data is getting Big. All is not lost, though. It is challenging, and it does take a slightly different approach, but dealing with oodles of research data is not as terrifying as it seems. In this talk I aim to give researchers some practical ideas on working with “big” research data, illustrated with examples of how we manage stuff like this at EPCC.
Jos Martin, Mathworks
Talk: "Software engineering in practise"
Abstract: Jos will discuss how MathWorks develop and extend MATLAB and its associated tools from an engineering perspective. Focusing on the opportunities – and challenges – in ensuring MATLAB continues to be the tool of choice in the world of multicore CPUs, in grids and clouds, on mobile platforms, and on GPUs. He discusses the processes involved in developing and testing MATLAB to drive usability features, development environment enhancements, and overall reliability.
Bio: Jos Martin is the senior engineering manager for parallel computing products at MathWorks. He has responsibility for all parts of Parallel Computing Toolbox, including the use of GPU and big data types in other areas. In addition, he is also responsible for MATLAB Drive, MATLAB Connector, and products that help link the desktop to the cloud. Before moving to a development role within MathWorks, he worked as a consultant in the U.K., writing large-scale MATLAB applications, particularly in the finance and automotive sectors. Prior to joining MathWorks in 2000, he held a Royal Society Post-Doctoral Fellowship at the University of Otago, New Zealand. His area of research was Experimental Bose-Einstein Condensation (BEC), a branch of low-temperature atomic physics.
Dr Patricio Ortiz, University of Sheffield
Talk: "Tackling the learning curve of scientific programming"
Abstract: Programming is part of the curriculum of students of computer science, and it will be complemented with other related subjects to make them knowledgeable on the subject. The situation of a science or engineering student is the opposite; typically they have one course to learn one language, and that language is usually not the one they will first face in real-life situations. This situation has occurred for decades, and it is likely not going to change, but there is a real need to better prepare science and engineering students to face the very steep learning curve of having to start programming as part of an ongoing project or their thesis.
Universities like ours offer excellent facilities like the HPCs supplied by IT Services, yet the reality is that many students and young researchers may have never used a Unix based system, let alone a parallel system.
The book I wrote, “first steps in scientific programmings” aims at facilitating the passage through the learning curve by providing tips based on years of experience and my interaction with students and brilliant young researchers who did not have the opportunity to learn anywhere else the challenges which programming in a scientific environment involve.
I will briefly describe the points which I think are more important to emphasise, points which I’ve confirmed as important by interacting with other experienced researchers at the U. of Sheffield, who are trying to provide support for the people starting in this field.
Link for the book: https://sites.google.com/view/fsscientificprogramming/home
A supportive link: https://sites.google.com/a/sheffield.ac.uk/rcg/my-blog/research-computing-notes/firststepsinscientificprogramming
Bio: Patricio Ortiz holds a PhD. in astronomy from the University of Toronto, Canada. He has a keen interest in programming as a mean to create tools to help his research when no tools were available. He has taught at the graduate and undergraduate levels in subjects about astronomy, instrumentation, and applied programming. Throughout his career, Patricio has interacted with students at any level as well as post-graduates, helping him identify the most critical subjects needed by young scientists in the physical sciences and usually not covered by current literature. He has worked on projects involving automated super-nova detection systems; detection of fast moving solar system bodies, including Near-Earth objects and he was involved in the Gaia project (European Space Agency) for nearly ten years. Patricio also developed an ontology system used since its conception by the astronomical community to identify equivalent quantities. He also worked on an Earth Observation project, which gave him the opportunity to work extensively with high-performance computers, leading to his development of an automated task submission system which significantly decreases the execution time of data reduction of extended missions.
Patricio now works as a Research Software Engineer at the Department of Automatic Control and Systems Engineering at the University of Sheffield. He uses C, Fortran, Python, Java and Perl as his main toolkits, and as a pragmatic person, he uses the language which suits a problem best. Amongst his interests are: scientific data visualisation as a discovery tool, photography and (human) languages.

Peter Heywood, University of Sheffield
Talk: "Accelerating Road Network Simulations using GPUs"
Abstract: Road network Simulations are a vital tool used in the planning and management of transport network infrastructure. Large-scale simulations are computationally expensive tasks, taking many-hours for a single simulation to complete using multi-core CPU architectures, hindering the use of large-scale simulations.
Using Graphics Processing Units (GPUs) we demonstrate that both Macroscopic (top-down) simulations and Microscopic (bottom-up) simulations can be considerably accelerated using many-core architectures and novel fine-grained data-parallel algorithms.
A multi-GPU version of the SATURN macroscopic road network simulation package has been developed, demonstrating assignment performance improvements of over 11x compared to a multi-socket CPU. A FLAME GPU based microscopic simulation demonstrates performance improvements of up to 65x using a single GPU compared to the commercial multi-core microsimulation tool Aimsun.
Bio: Peter Heywood is a Research Software Engineer and PhD candidate at the University of Sheffield. His research is focussed on using Graphics Processing Units (GPUs) to improve the performance of complex systems simulations; including transport network simulation and biological cellular simulations. Peter has presented his work at multiple international conferences and recently publisheded his work in the Simulation Modelling Practice and Theory Journal.
David Hubber, Researcher at Ludwig-Maximilians-Universität Munich
Talk: "Structuring code efficiently"
Abstract: David will discuss how to structure code efficiently. He will also discuss code module design, decoupling strategies and test-driven development.
Bio: David Hubber is an astrophysicist by training that has worked extensively on writing software such as GANDALF and SEREN to simulate star forming regions. He has been a researcher at the university of Cardiff, the university of Sheffield, and is currently a Postdoc researcher Ludwig-Maximilians-Universitat Munich.
Dr Stephen McGough, Newcastle University
Talk: "PARALLEM: massively Parallel Landscape Evolution Modelling"
Abstract: Landscape Evolution Modelling (LEM) is used to predict how landscapes evolve over the millennia due to weathering and erosion. LEM’s normally operate on a regular grid of cells each representing the height of a point within a landscape. The process can be broken up into the following stages applied to each cell: determination of the flow direction of water out of that cell, summation of the volume of water flowing through the cell and computation of the erosion / deposition in the cell. This process is repeated at regular intervals - either an annual time-step (due to computation complexity) or once for each major storm-event - for periods of around one million years.
Within each year/rainstorm there is great potential for speedup when executing on a GPGPU - flow direction for most cells can be performed independently, flow accumulation can easily be performed in parallel. However, due to certain ‘real world’ landscape features this potential can easily be lost. Landscape features such as plateaus - where all cells in a region have the same height - or sinks - (sets of) cells which have no lower neighbour, meaning water cannot escape - prevent optimal speedup being achieved. Likewise, computing the volume of water passing through a cell is inherently sequential - the sum of water through a cell at the end of a river depends on knowing the volume of water passing through all points upstream.
CUDA algorithms have been developed for computing the LEM processes: Flow direction can be computed independently for each cell; A parallel breadth-first algorithm can be used for routing water over a plateau to an outlet cell; A parallel technique for ‘filling’ sinks (making them into lakes) which performs much of its work through parallel pointer jumping is used. Flow accumulation can be performed using a developed ‘correct’ algorithm where each cell which has no incorrect flows entering it can be computed and marked correct. The process of erosion / deposition can then be performed in a similar manner to flow accumulation with the eroded material being passed around.
In this talk we will present parallel techniques for overcoming these problems, demonstrating between two and three orders of magnitude speedup over the best-in- class LEM software for landscapes between 0.1 and 56 million cells - far larger than the traditional 5 thousand cell simulations which have previously been performed. This has led to a need for a re-evaluation of the models used within the LEM community. Errors in LEM simulation results, which have been used over the last 30+ years, have been attributed to the very small simulation sizes. However, with our 46+ million cell simulations - a realistic scale - we are now able to determine that these errors are not due to scale but rather due to the equations themselves.
We will present our approach moving forwards to overcome these limitations and present initial results of this work.
Bio: Dr Stephen McGough is a Senior Lecturer in the School of Computing at Newcastle University, UK. He obtained his PhD in the area of Parallel simulation and has worked for many years in the areas of parallel computing and simulation. Holding posts at Imperial College London, UCL, Newcastle University and Durham University. This has led to over fifty publications in the area of parallel computing including receiving the NVIDIA best paper award at HiPC 2012. His research focuses on the use of novel computing technologies, such as GPGPU, to solve real-world challenges.

Dr Thomas Nowotny, University of Sussex
Talk: "Opportunities and challenges for spiking neural networks on GPUs"
Abstract: In the past 6 years, we have developed the GeNN (GPU enhanced neuronal networks) framework for GPU accelerated spiking neuronal network simulations. In essence, GeNN is based on a simple design of code generation that allows a large extent of flexibility for computational models while at the same time taking care of some of the GPU specific optimisation work in the background. In this talk I will present the main features of GeNN, its design principles and show benchmarks. I will then discuss limitations, both specific to GeNN and to numerical simulation work on GPUs more generally and present some further work, including the SpineML-GeNN and Brian2GeNN interfaces. GeNN is developed within the Green Brain http://greenbrain.group.shef.ac.uk/ and Brains on Board http://brainsonboard.co.uk/ projects and is available under GPL v2 at Github http://genn-team.github.io/genn/.
Bio: Thomas Nowotny received his PhD in theoretical physics in 2001 from the University of Leipzig and worked for five years at the University of California, San Diego. In 2007 he joined the University of Sussex, where he is now a Professor of Informatics and the Director for Research and Knowledge Exchange at the School of Engineering and Informatics. His research interests include olfaction in animals and machines, GPU accelerated scientific computing, hybrid brain-computer systems and bio-inspired machine learning.

Twin Karmakharm, Research Software Engineer, University of Sheffield
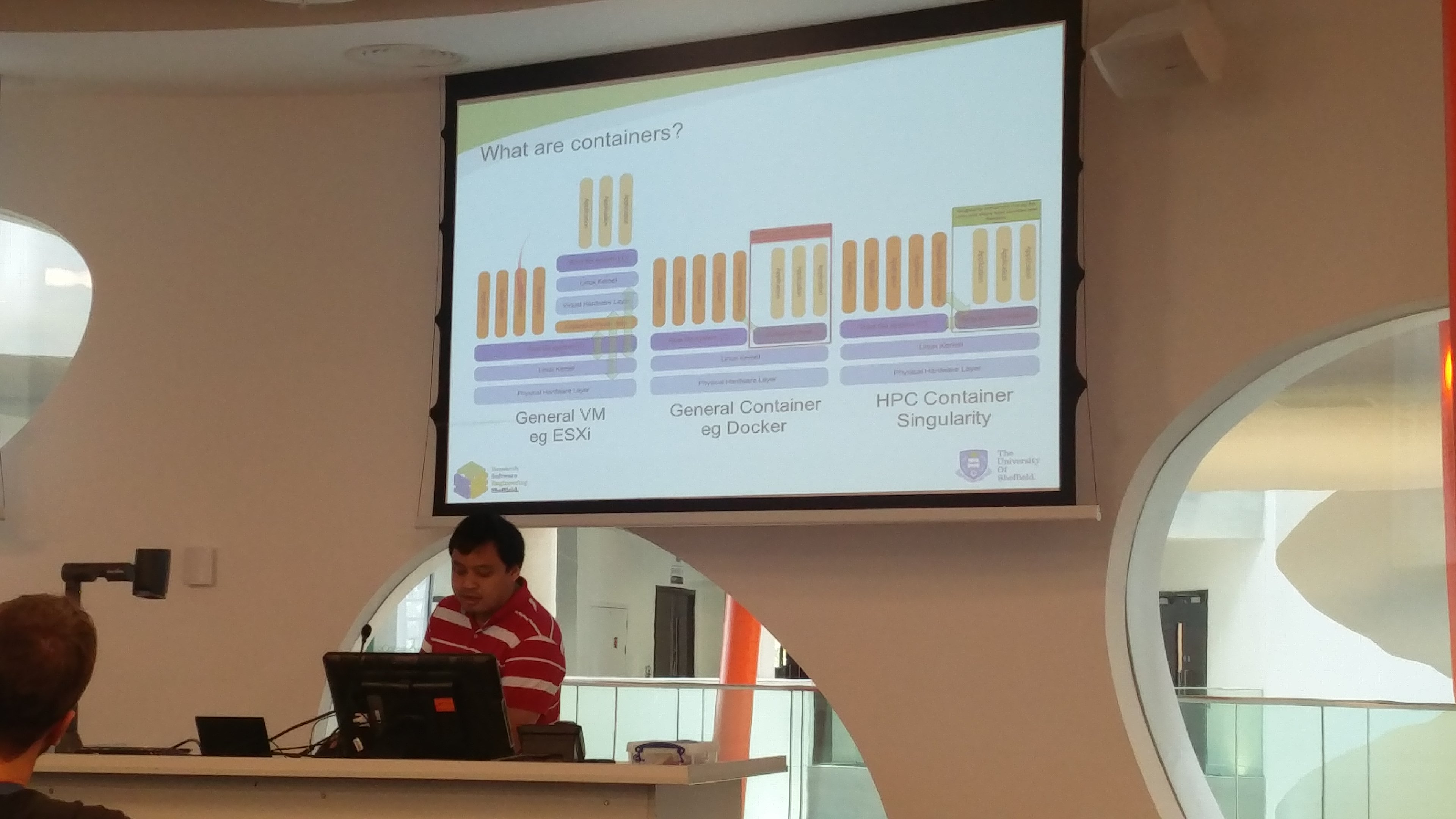
Talk: "Containers for High Performance Computing"
Abstract: Containerization is a lightweight virtualisation technology where users can package workflows, software, libraries and data for running on various machines with minimal loss of performance. The technology can be used a way for scientists to deploy custom software on the HPC cluster and easily share reproducible software along with their data. The talk explores the concept of containers and existing container technologies suitable for the HPC. Particular focus is given for Singularity which has recently been introduced on the new Sheffield Advance Research Computer (ShARC) cluster.
Ania Brown, Research Software Engineer, Oxford e-Research Centre
Talk: "Towards achieving GPU-native adaptive mesh refinement"
Abstract: Modern simulations model increasingly complex multiscale systems, and the need to capture details at multiple length scales can lead to large memory requirements. Adaptive mesh refinement (AMR) is a method for reducing memory cost by varying the accuracy in each region to match the physical characteristics of the simulation, at the cost of increased data structure complexity. This complexity is a particular problem on the GPU architecture, which is most naturally suited to regular data sets. I will describe some of the optimisation and software challenges that need to be considered when implementing AMR on GPUs, based on my experience working on a GPU-native framework for stencil calculations on a tree-based adaptively refined mesh as part of my Master degree. Topics covered will include achieving coalesced access with the AMR data structure, memory defragmentation after grid changes and load balancing using space-filling curves.
Bio: Ania is a research software engineer at the Oxford e-Research Centre. Her research interests are a combination of performance optimisation for large scale scientific simulation and software development methodology to improve the quality of such codes. She received her Master degree from the Tokyo Institute of Technology in 2015.

Paul Richmond, Research Software Engineer, Sheffield
Talk: "Performance Optimisation for GPU computing in CUDA"
Paul Richmond gave a two hour lecture on Performance Optimisation for GPU computing in CUDA. The lecture is part of COM4521 on GPU computing but any CUDA developers who were keen on optimising their code were invited to attend.
Mike Croucher, Research Software Engineer, Sheffield
Talk: "Project Jupyter and SageMathCloud"
Mike Croucher gave a presentation at the University of Sheffield Chemical Engineering teaching away day on the use of `Project Jupyter and SageMathCloud http://mikecroucher.github.io/ChemEng_Jupyter_talk2016/ for teaching computational subjects.
For queries relating to collaborating with the RSE team on projects: rse@sheffield.ac.uk
Information and access to Bede.
Join our mailing list so as to be notified when we advertise talks and workshops by subscribing to this Google Group.
Queries regarding free research computing support/guidance should be raised via our Code clinic or directed to the University IT helpdesk.
List of archived pages: Archive.